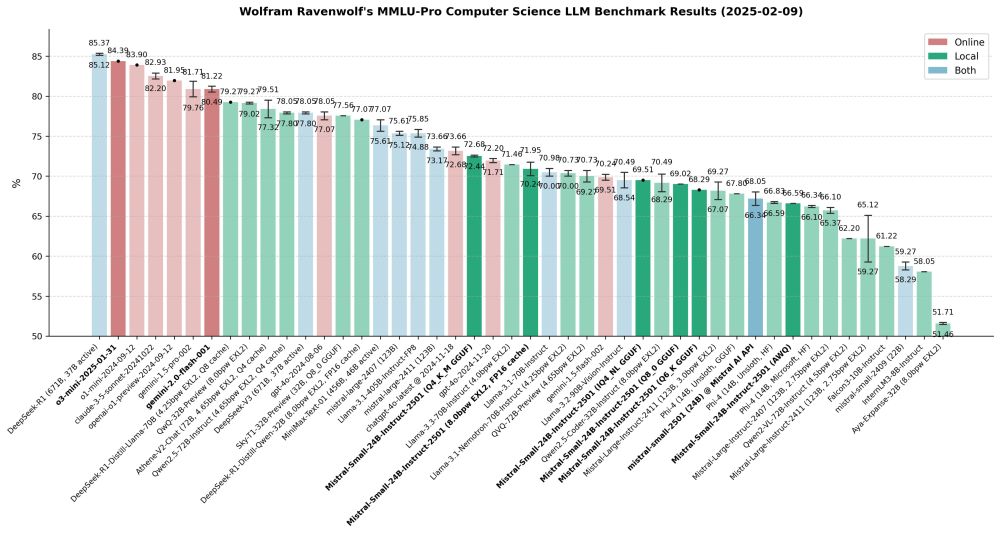
Here's a quick update on my recent work: Completed MMLU-Pro CS benchmarks of o3-mini, Gemini 2.0 Flash and several quantized versions of Mistral Small 2501 and its API. As always, benchmarking revealed some surprising anomalies and unexpected results worth noting:
Feb 10, 2025 22:36o3-mini takes 2nd place, right behind DeepSeek-R1, ahead of o1-mini, Claude and o1-preview. Not only is it better than o1-mini+preview, it's also much cheaper: A single benchmark run with o3-mini cost $2.27, while one run with o1-mini cost $6.24 and with o1-preview even $45.68!
Gemini 2.0 Flash is almost exactly on par with 1.5 Pro, but faster and cheaper. Looks like Gemini version 2.0 completely obsoletes the 1.5 series. This now also powers my smart home so my AI PC doesn't have to run all the time.
Mistral-Small-24B-Instruct-2501 is amazing for its size, but what's up with the quants? How can 4-bit quants beat 8-bit/6-bit ones and even Mistral's official API (which I'd expect to be unquantized)? This is across 16 runs total, so it's not a fluke, it's consistent! Very weird!