Benjamin Warner
R&D at answer.ai
- [Not loaded yet]
- There isn't a canonical version, but there are retrieval models from GTE and Nomic which might work for your task. GTE: huggingface.co/Alibaba-NLP/... Nomic: huggingface.co/nomic-ai/mod...
- One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head? Spoilers: the answer is yes.
-
View full threadCan all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM? No. And it's not close.
- For more details, including our simple training method, see Benjamin Clavié's twitter announcement, our model, blog post, and paper. Twitter: x.com/bclavie/stat... Model: huggingface.co/answerdotai/... Blog: www.answer.ai/posts/2025-0... Paper: arxiv.org/abs/2502.03793
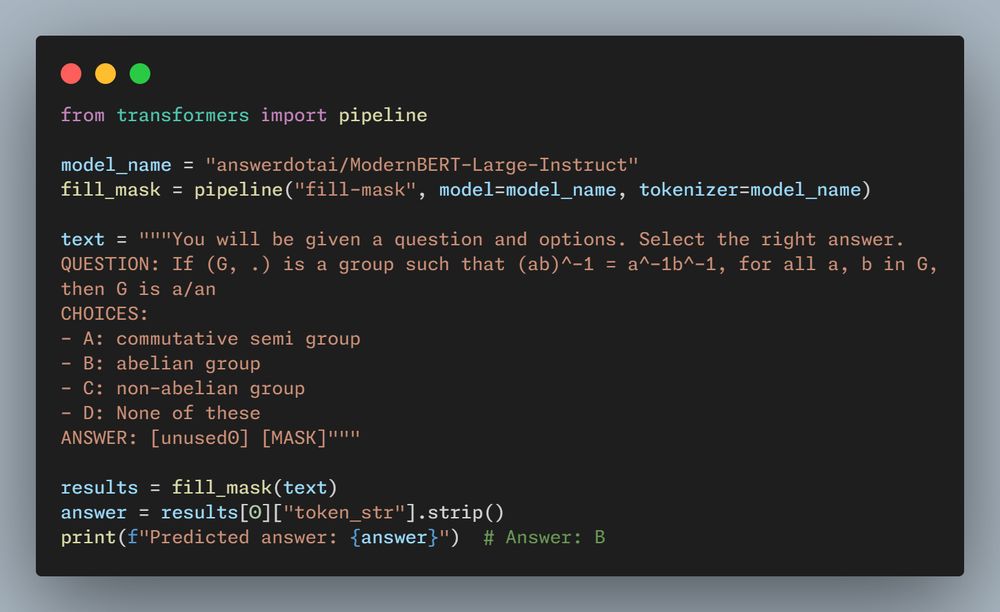
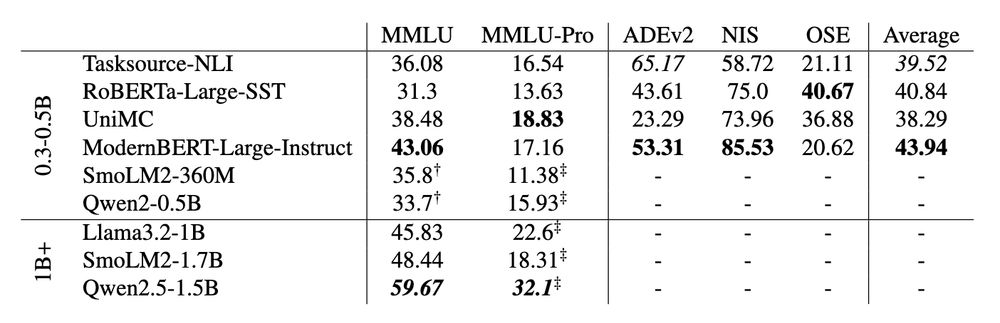
- After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
- When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.
- With @bclavie.bsky.social and @ncoop57.bsky.social, we tried to answer two questions: - Can an instruction-tuned ModernBERT zero-shot tasks using the MLM-head? - Could we then fine-tune instruction-tuned ModernBERT to complete any task? Detailed answers: arxiv.org/abs/2502.03793
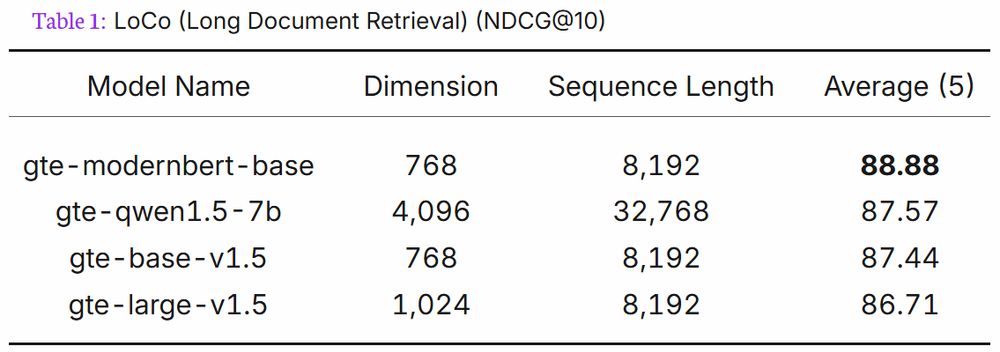
- In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card: gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
- You can find the models on Hugging Face here: - gte-modernbert-base: huggingface.co/Alibaba-NLP/... - gte-reranker-modernbert-base: huggingface.co/Alibaba-NLP/...
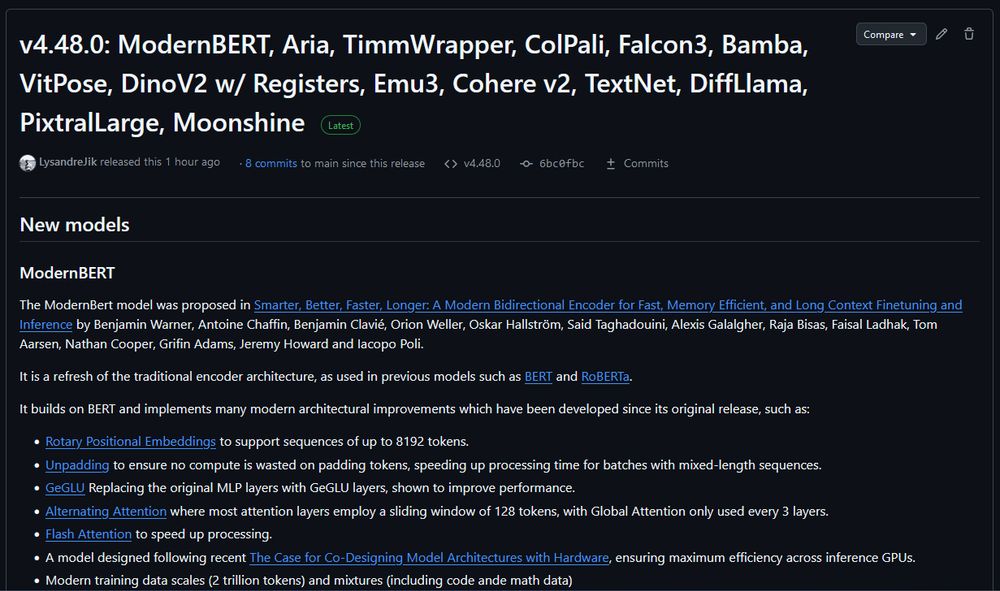
- ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use. If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
- What's ModernBERT? It's a drop-in replacement for existing BERT models, but smarter, faster, and supports longer context. Check out our announcement post for more details: huggingface.co/blog/modernb...
- The good: 32GB The bad: $2,000 The Ugly*: PCIe 5 without NVLink
- *Actually, that’s good compared to the 4090’s PCIe 4 without NVLink
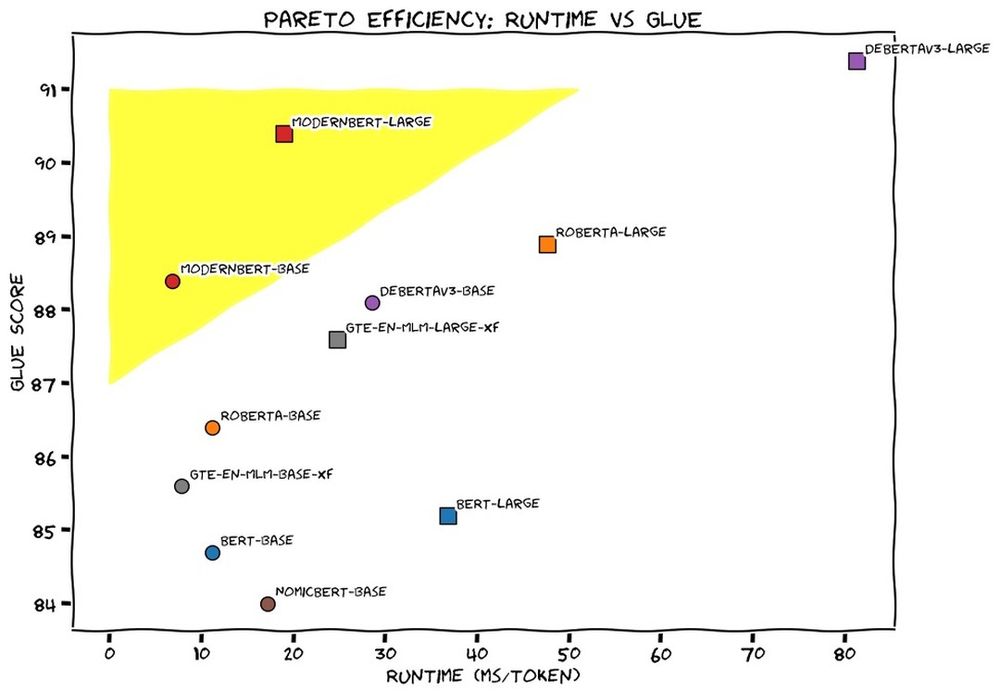
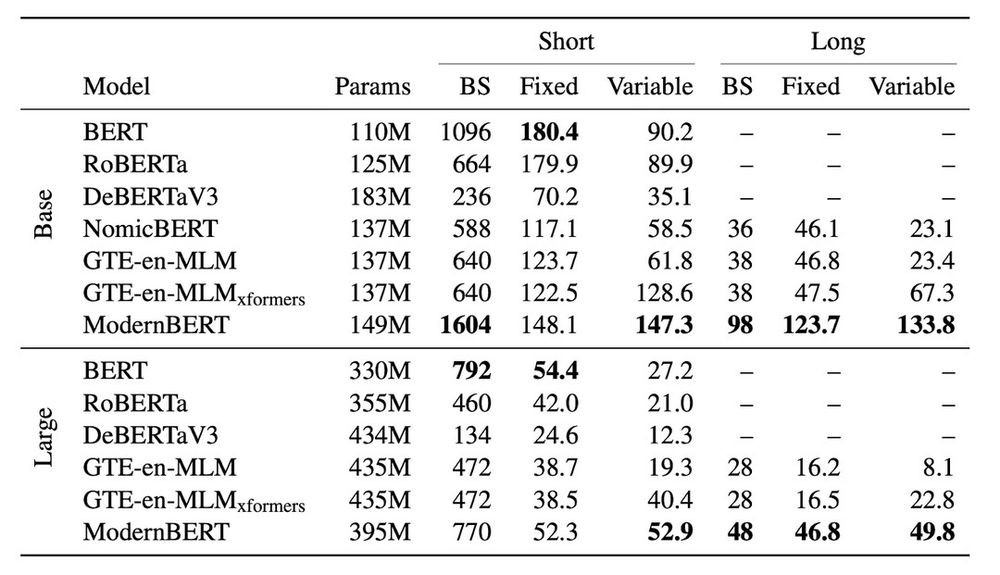
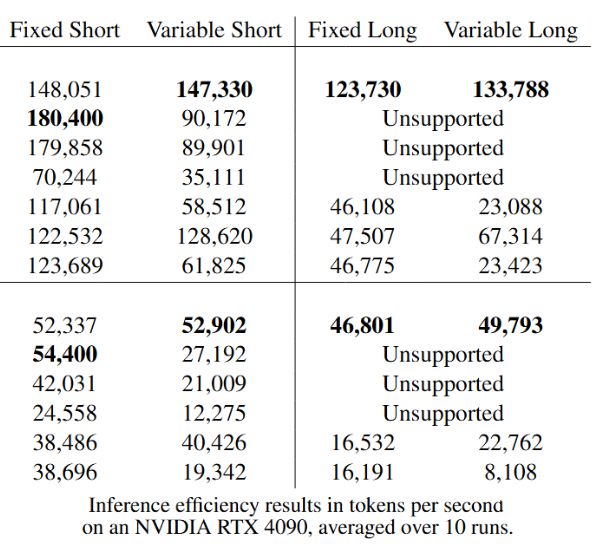
- This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
- [Not loaded yet]
- ModernBERT is a “foundation model” so you’ll either need to finetune it for entailment/NLI or wait for someone else to finetune it. I suspect it would be good at NLI once finetuned.
- [Not loaded yet]
- We evaluated ModernBERT on MLDR using ColBERT-style retrieval using that code. That process was smaller scale than a full ColBERT finetune, which would need additional contrastive training, likely use multiple teacher models, etc as detailed here by @bclavie.bsky.social www.answer.ai/posts/2024-0...
- [Not loaded yet]
- Thanks. ModernBERT is a base model. It’ll need additional contrastive pretraining to really shine as a retrieval model, but our early results in the paper look promising. Hopefully there will be multiple open source retrieval tuned models to choose from early next year, including ColBERT finetunes.
- [Not loaded yet]
- Thanks for the kind words. We tried to fit as much information within our page limit as possible and have a comprehensive appendix. As far as the name goes, all I’ll say is be careful not to use an overly strong code name.
- [Not loaded yet]
- Thanks. It’ll need additional contrastive pretraining to really shine as a retrieval model, but our early results look promising. Hopefully there will be multiple open source retrieval tuned models to choose from early next year.
- (early results in our paper)
- I'm looking forward to seeing what you all will build with a modern encoder.
- PS: BlueSky needs to make their really long account tags not count against the character limit.
- Thanks to my two co-leads: @nohtow.bsky.social , @bclavie.bsky.social , & the rest of our stacked author cast: @orionweller.bsky.social, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, @tomaarsen.com , @ncoop57.bsky.social , Griffin Adams, @howard.fm , & Iacopo Poli
- A big thanks to Iacopo Poli and @lightonai.bsky.social for sponsoring the compute to train ModernBERT, @bclavie.bsky.social for organizing the ModernBERT project, and to everyone who offered assistance and advice along the way. Also h/t to Johno Whitaker for the illustrations.
- Last, we trained ModernBERT on variety of data sources, including web docs, code, & scientific articles, for a total of 2 trillion tokens of English text & code. 1.7 trillion tokens at a short 1024 sequence length, followed by 300 billion tokens at a long 8192 sequence length.
- For all the model design, training, and evaluation details, check out our Arxiv preprint: arxiv.org/abs/2412.13663
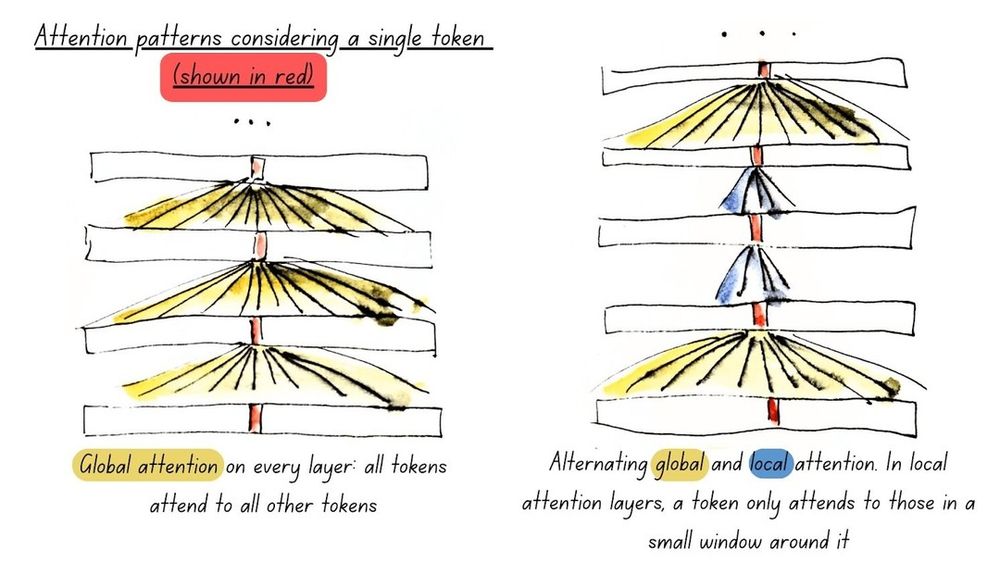
- How did we do it? First, we brought all the modern LLM architectural improvements to encoders, including alternating global & local attention, RoPE, and GeGLU layers, and added full model unpadding using Flash Attention for maximum performance (illustrated in the next post).
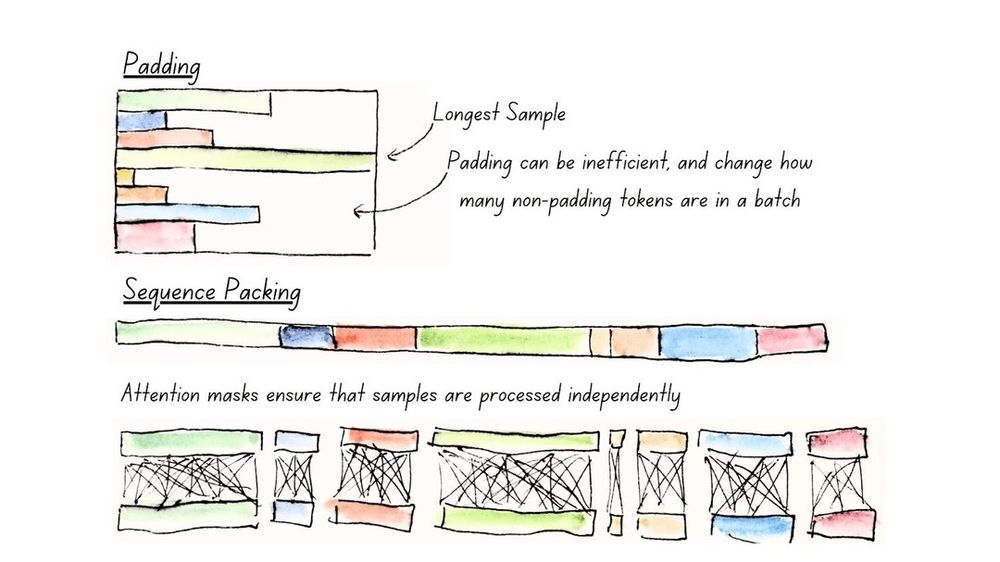
- Second, we carefully designed ModernBERT's architecture run to efficiently across most common GPUs. Many common older models don't consider the hardware they will run on and are slower than they should be. Not so with ModernBERT. (Full model sequence packing illustrated below)
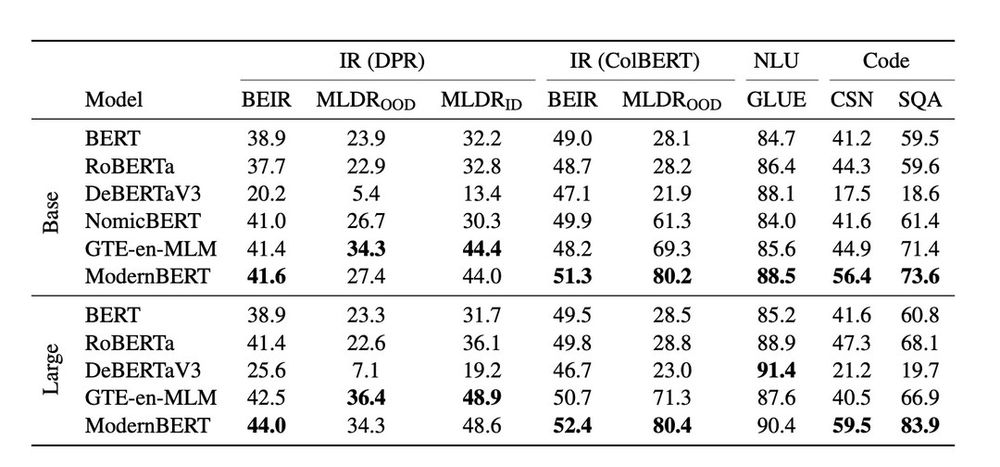
- ModernBERT-base is the first encoder to beat DeBERTaV3-base on GLUE. ModernBERT is also competitive or top scoring on single vector retrieval, ColBERT retrieval, and programming benchmarks.
- ModernBERT was designed from the ground up for speed and memory efficiency. ModernBERT is both faster and more memory efficient than every major encoder released since the original BERT.
- ModernBERT is available to use today on Transformers (pip install from main). More details in our announcement post. huggingface.co/blog/modernb...
- [Not loaded yet]
- Good codenames are dangerous, as they have staying power.
- I feel the need for speed.