Benjamin Warner
R&D at answer.ai
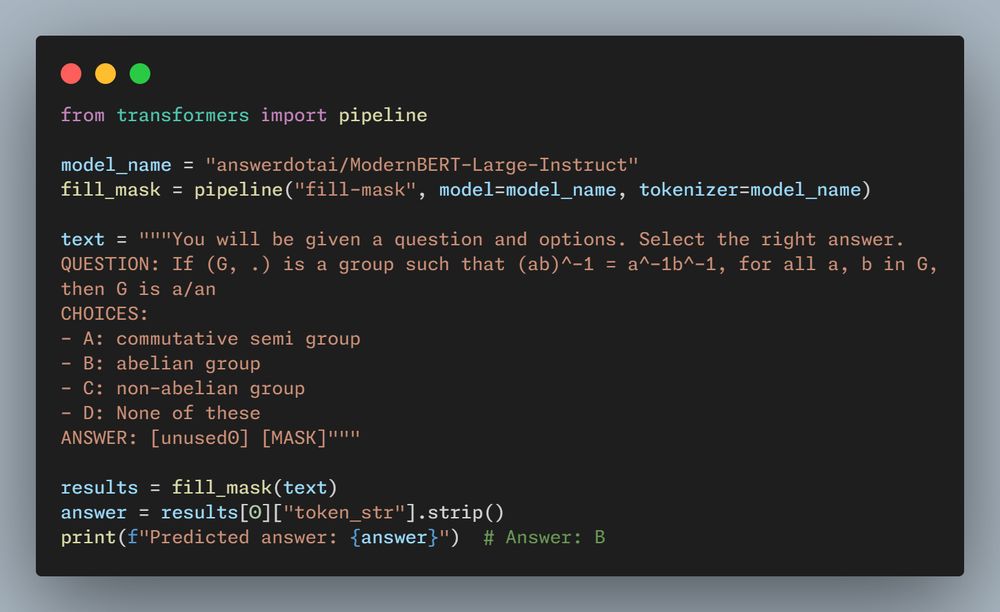
- One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head? Spoilers: the answer is yes.
- Reposted by Benjamin Warner[Not loaded yet]
- Reposted by Benjamin Warner[Not loaded yet]
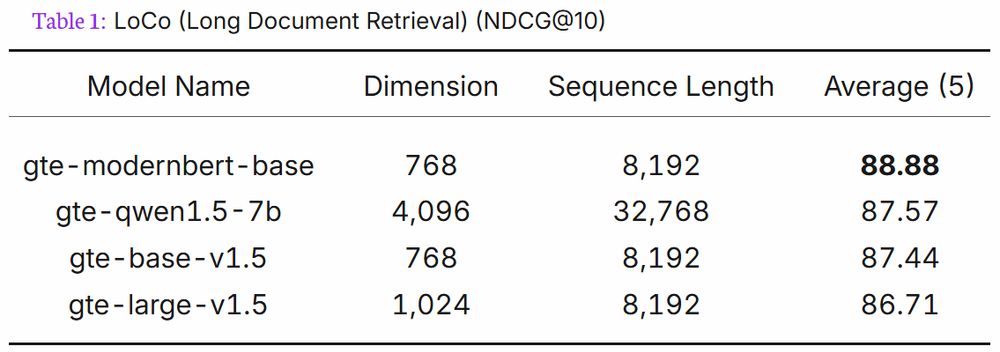
- In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card: gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
- Reposted by Benjamin Warner[Not loaded yet]
- Reposted by Benjamin Warner[Not loaded yet]
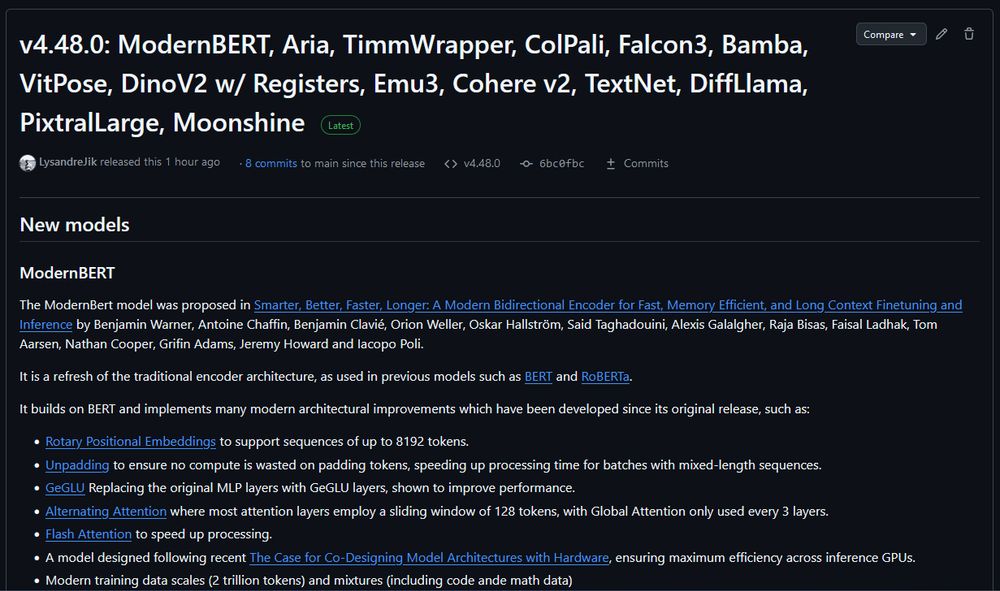
- ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use. If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
- The good: 32GB The bad: $2,000 The Ugly*: PCIe 5 without NVLink
- Reposted by Benjamin Warner[Not loaded yet]
- Reposted by Benjamin Warner[Not loaded yet]
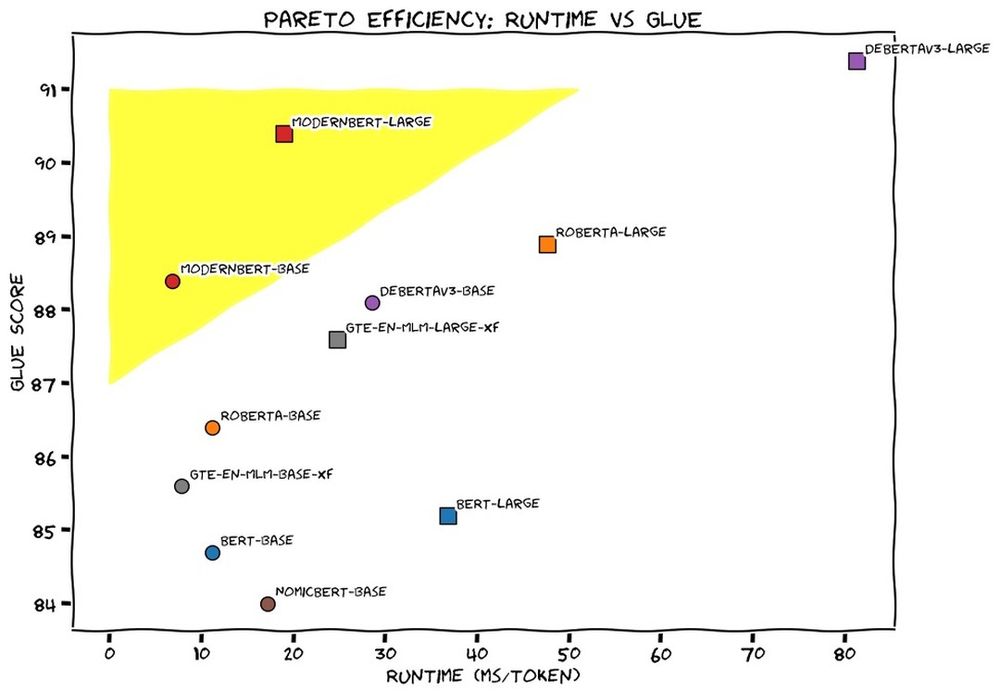
- This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
- Reposted by Benjamin Warner[Not loaded yet]