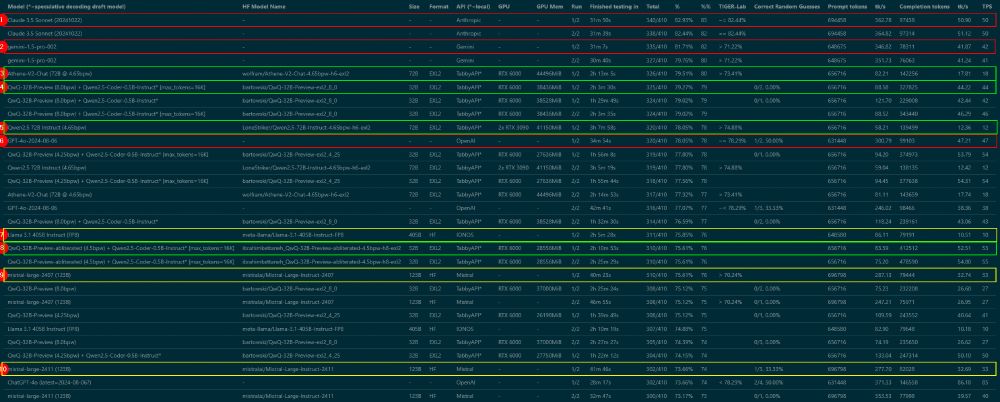
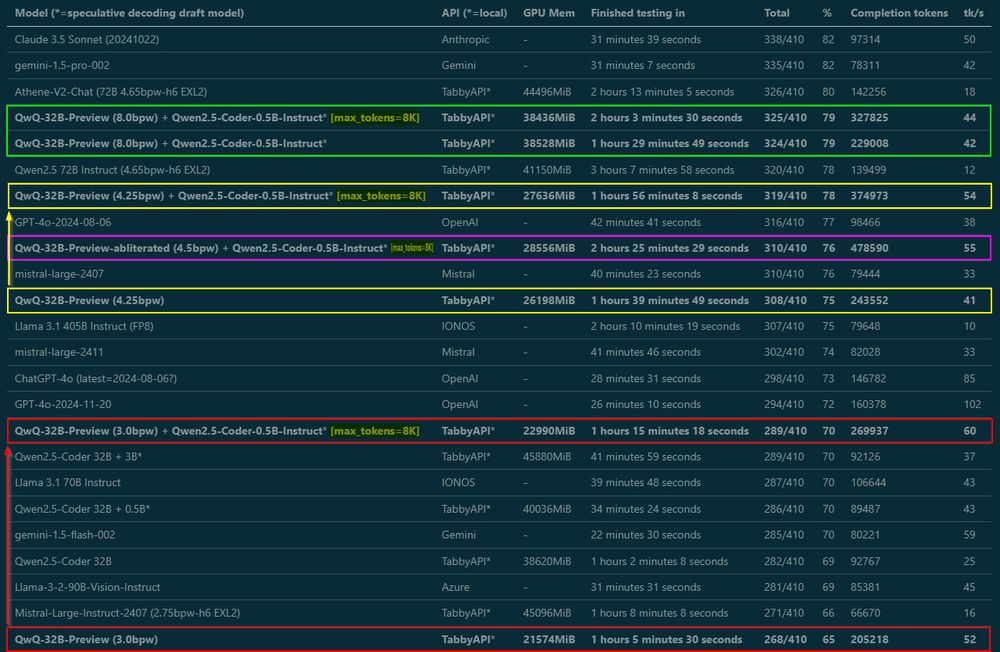
- Benchmark Progress Update: I've completed ANOTHER round to ensure accuracy - yes, I have now run ALL the benchmarks TWICE! While still compiling the results for a blog post, here's a sneak peek featuring detailed metrics and Top 10 rankings. Stay tuned for the complete analysis.
- Almost done benchmarking, write-up coming tomorrow – but wanted to share some important findings right away: Tested QwQ from 3 to 8 bit EXL2 in MMLU-Pro, and by raising max_tokens from default 2K to 8K, smaller quants got MUCH better scores. They need room to think!
- I'll probably go with average scores to determine rank - which means QwQ-32B-Preview (8bpw, 16K max new tokens) at 324.5 vs Athene-V2-Chat at 321.5 takes the lead as best local model (in my rankings)!