Jade
Researcher @nousresearch.com
- "Has anyone tried... oh, it's already in the NanoGPT speedruns"
- [Not loaded yet]
- the woke lesson
- Dynamically scaled softplus attention Builds on log-scaled attention, replacing the softmax exp with softplus but keeping the normalization. Reminiscent of sigmoid attention - which it reports as also outperforming softmax results when applying the same modifications. arxiv.org/abs/2501.13428
- Some focus has been given to sigmoid attention recently due to newer results, but I first came across it in Shatter from 2021, where it was proposed for single-headed attention. arxiv.org/abs/2108.13032
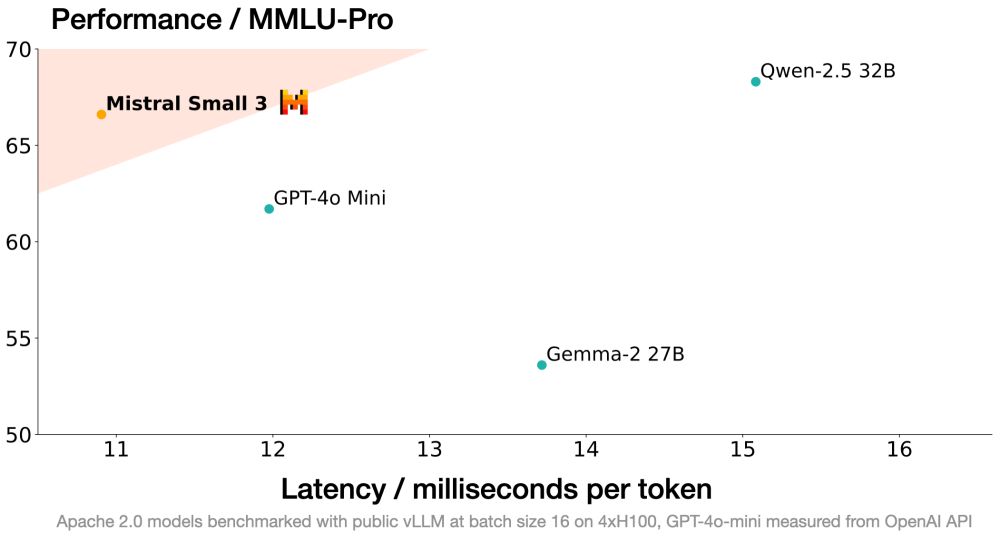
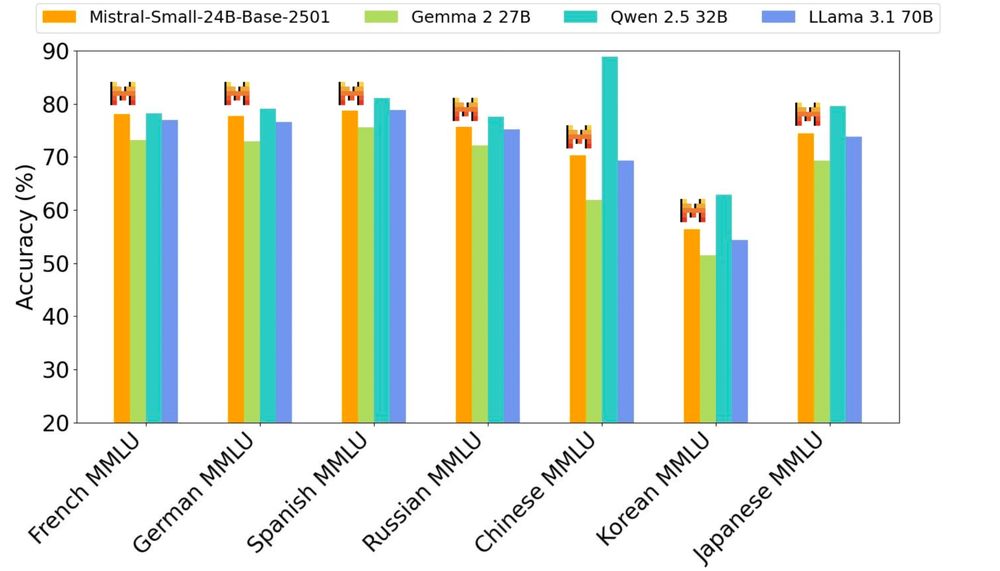
- New Mistral model just dropped mistral.ai/news/mistral...
- 24B
- A general framework for constructing sequence models via test-time regression. This sort of idea has been floating around for a while, but we haven't done much with it, with a few mostly-recent exceptions (e.g. TTT, Titans). arxiv.org/abs/2501.12352
- [Not loaded yet]
- [Not loaded yet]
- like TTT?
- Interesting and somewhat unintuitive: Distilling reasoning by placing the teacher CoT post-answer performs better than prefixing, suggesting that the student isn't learning to do CoT. Further, permuting the CoT tokens doesn't harm performance, and only a small number of the tokens are needed.
- It's also not just more tokens - tokens not from the CoT reationale don't match the CoT performance, even though heavily corrupted CoTs work fine
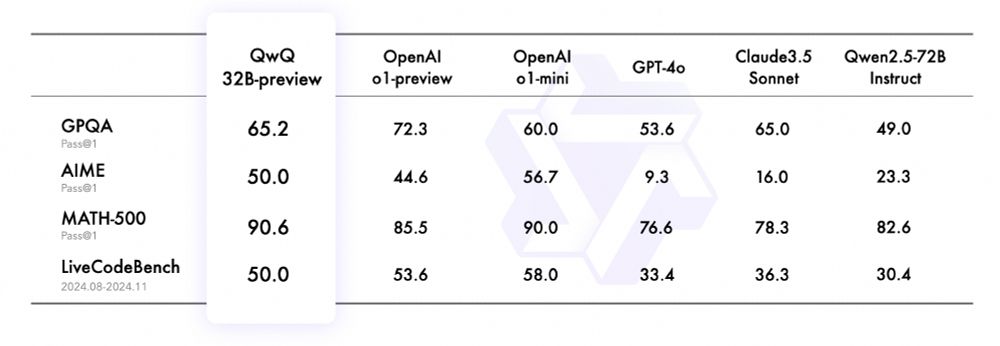
- Qwen team at the forefront of open AI, as usual
- QwQ: Reflect Deeply on the Boundaries of the Unknown What you see with these new models is that they don't need reflection tokens, but simply benefit a lot from self-talk. qwenlm.github.io/blog/qwq-32b...
- OpenAI really needs to rename
- There now seems to be an HF group for such projects: huggingface.co/bluesky-comm...
- [Not loaded yet]
- I use "Popular with friends" by default. I really didn't like Discover
- [Not loaded yet]
- technically I am not anon
- [Not loaded yet]
- this was an instant follow
- arxiv.org/abs/2411.12537 arxiv.org/abs/2405.17394 Allowing non-negative gates widens the class of regular expressions, specifically for periodic state tracking (e.g. modular counting, bitstring parity) I had a similar thought back when I was first toying with linear RNNs, so I had tried tanh.
- Regarding periodicity in general, another thing I had expiremented with at some points was just inserting periodic position encodings, inspired by arxiv.org/abs/2402.00236
- I wonder if keeping track of cumulative multipliers like in LRNNs, but then using them as a soft mask for attention, would help this in transformers. Sort of like CoPE arxiv.org/abs/2405.18719
- try to fix NaNs -> model trains until it randomly kills the machine try to fix model killing the machine -> model too slow try to fix slowness -> NaN try to fix NaNs -> loss doesn't go down 🙃
- Yet another proposal for an attention variant allowing for negative weights arxiv.org/abs/2411.07176