Jade
Researcher @nousresearch.com
- Reposted by JadeWe're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.
- Reposted by JadeWe created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words. When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
- Reposted by JadeI really feel like fashion retail websites should let you browse in latent space. Don't select a category like "shirt". Instead, see some product images, and select one that's a shirt. Then see a grid of shirts, and pick your favorites. See a grid of shirts like these. Repeat.
- "Has anyone tried... oh, it's already in the NanoGPT speedruns"
- Dynamically scaled softplus attention Builds on log-scaled attention, replacing the softmax exp with softplus but keeping the normalization. Reminiscent of sigmoid attention - which it reports as also outperforming softmax results when applying the same modifications. arxiv.org/abs/2501.13428
- New Mistral model just dropped mistral.ai/news/mistral...
- Reposted by JadeRecent AI breakthroughs challenge the status quo narrative that only closed, mega labs have the ability to push the frontier of superintelligence. Today we announce Nous Psyche built on @solana.com www.youtube.com/watch?v=XMWI...
- A general framework for constructing sequence models via test-time regression. This sort of idea has been floating around for a while, but we haven't done much with it, with a few mostly-recent exceptions (e.g. TTT, Titans). arxiv.org/abs/2501.12352
- Reposted by Jadethe o3 announcement feels very analogous to the GPT-3 announcement in early 2020: "here is new tech, it's very powerful, but it's super expensive to run and we're super selective with who we give access to"
- Reposted by Jade“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
- Interesting and somewhat unintuitive: Distilling reasoning by placing the teacher CoT post-answer performs better than prefixing, suggesting that the student isn't learning to do CoT. Further, permuting the CoT tokens doesn't harm performance, and only a small number of the tokens are needed.
- Qwen team at the forefront of open AI, as usual
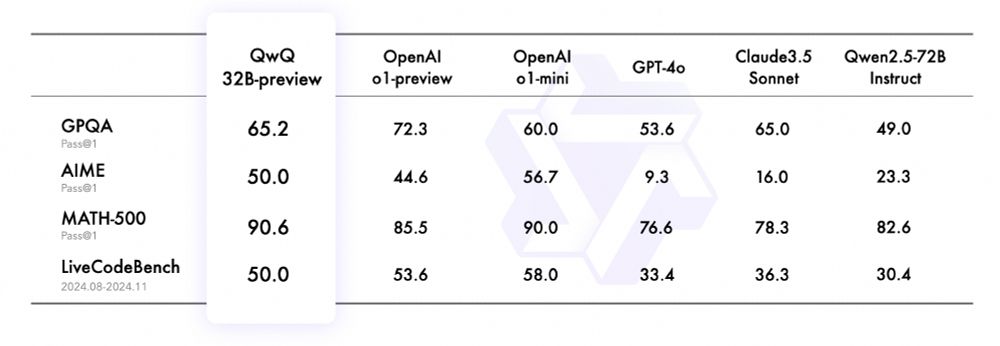
- QwQ: Reflect Deeply on the Boundaries of the Unknown What you see with these new models is that they don't need reflection tokens, but simply benefit a lot from self-talk. qwenlm.github.io/blog/qwq-32b...
- Reposted by JadeHow to publish your Bluesky scrape without anybody noticing: zenodo.org/records/1108...
- There now seems to be an HF group for such projects: huggingface.co/bluesky-comm...
- Reposted by Jadetheres a new kaggle challenge for building an efficient chess bot that fits within 64KiB www.kaggle.com/competitions...
- Reposted by JadeSo first version of an ml anon starter pack. go.bsky.app/VgWL5L Kept half-anons (like me and Vic). Not all anime pfp, but generally drawn.at://did:plc:vg3thtvfbgfrr3u6pf6hy3yk/app.bsky.graph.starterpack/3lbphjvucu32k
- arxiv.org/abs/2411.12537 arxiv.org/abs/2405.17394 Allowing non-negative gates widens the class of regular expressions, specifically for periodic state tracking (e.g. modular counting, bitstring parity) I had a similar thought back when I was first toying with linear RNNs, so I had tried tanh.
- try to fix NaNs -> model trains until it randomly kills the machine try to fix model killing the machine -> model too slow try to fix slowness -> NaN try to fix NaNs -> loss doesn't go down 🙃
- Yet another proposal for an attention variant allowing for negative weights arxiv.org/abs/2411.07176