Epoch AI
We are a research institute investigating the trajectory of AI for the benefit of society.
epoch.ai
- We're hiring! Epoch AI is looking for a Head of Web Development. In this role, you would: - Help communicate our research while managing sustainable infrastructure - Manage a team of 3-5 engineers - Align our tech stack with the organization's long-term goals
- The role is remote and we can hire in many countries. Applications are rolling! Apply here: careers.epoch.ai/en/postings/...
- We’re hiring an Engineering Lead to help guide our Benchmarking team! Provide independent evaluations of today’s and tomorrow’s AI models, leading to better research, policy, and decision-making. The role is fully remote, and applications are rolling.
- Apply now! careers.epoch.ai/en/postings/...
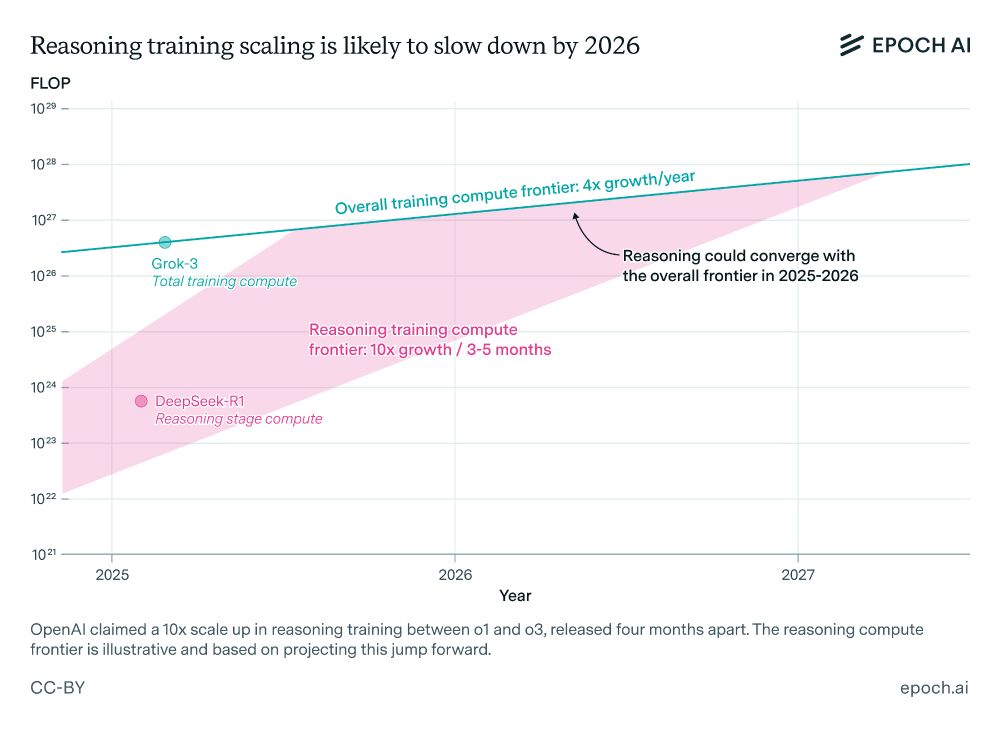
- Can AI developers continue scaling up reasoning models like o3? @justjoshinyou.bsky.social reviews the available evidence in this week’s Gradient Update, and it appears that the rapid scaling of reasoning training, like the jump from o1 to o3, will likely slow down in a year or so.
-
View full threadTraining compute at the frontier grows ~4× per year, so labs can’t continue to scale up reasoning training by 10× every few months — as OpenAI did from o1 to o3 — once reasoning training compute approaches the overall frontier.
- There could still be rapid algorithmic improvements after the reasoning scaling slows down, but at least one factor in the recent pace of progress in reasoning models is not sustainable. Check out the full newsletter issue below! epoch.ai/gradient-upd...
- Another hint is that Anthropic CEO Dario Amodei suggested in January that reasoning training to date has scaled to $1M per model, or ~5e23 FLOP. But it’s unclear if Amodei is referring to particular models here or has good insight into non-Anthropic models.
- So reasoning training probably isn’t yet at the scale of the largest pre-training runs (>1e26 FLOP), but it’s unclear exactly how far o1 and o3 are from the frontier. However, the pace of growth is so rapid that we know that the rate of scale-ups can’t continue for long.
- How much training compute is used for reasoning training now? OpenAI hasn’t said how much compute they used to train o3, but o3 was trained on 10× more compute than o1 (released four months prior). This probably refers to RL reasoning training compute, not total compute.
- So what’s the scale of o1 and o3 in absolute terms? We could get hints from similar models. For example, DeepSeek-R1 was trained on ~6e23 FLOP in the reasoning stage. Nvidia’s Llama-Nemotron Ultra is at a similar scale. x.com/EpochAIResea...