David Berenstein
ML & DevRel (synthetic) data quality @ Hugging Face 🤗
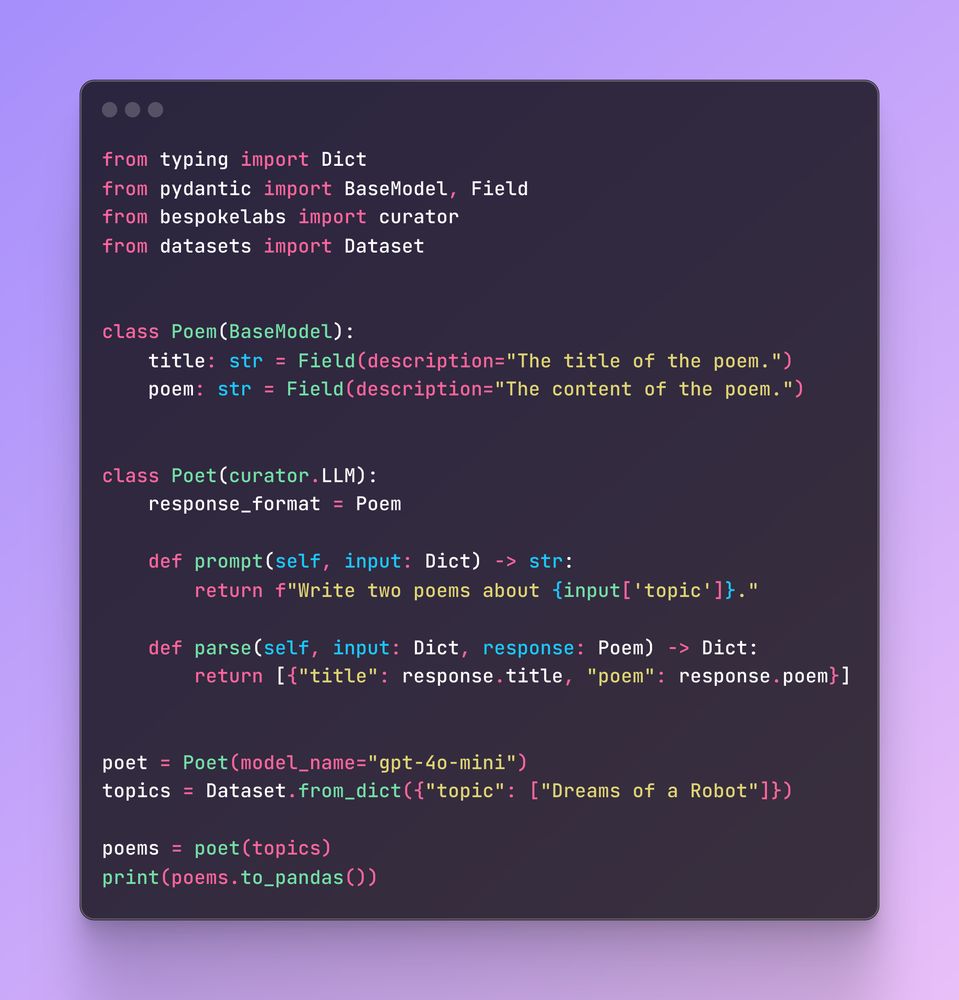
- 🔥 Bespoke curator: Synthetic Data Curation for Post-Training & Structured Data Extraction Create synthetic data pipelines with easy! - Retries and caching included - inference via LiteLLM, vLLM, and popular batch APIs - asynchronous operations 🔗 URL: buff.ly/ajPRT1l
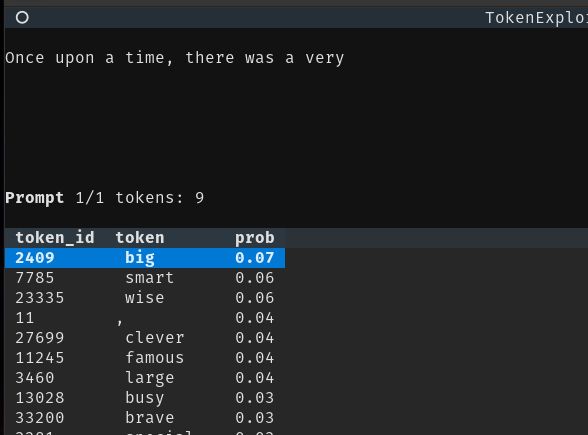
- 🔥One > token > at > a > time < a < at < token < One 🔥 token-explorer is a simple tool that lets you explore different possible paths that an LLM might sample! - Arrow keys to navigate, pop and append tokens - View the token probabilities and entropies. GitHub: buff.ly/FQgsczM
- 🍽️ Let’s dissect the Synthetic Dataset Generator 💬 Natural language prompt to data 🦙 Ollama ensures secure local LLM inference ✍🏼 Argilla’s data curation capabilities complete the workflow 🔗 GitHub: buff.ly/5pX49Xc
- 🔥 Text2SQL, explore and share any data analysis! 🤗 Hugging Face - Dataset Studio is an amazing new feature. 🚀 Start yourself: buff.ly/pjpOKav
- 🔥 Vicinity: SEVEN semantic search BACK-ENDS, ONE single INTERFACE! 🫸 New release to push vector search to the Hub and work with any serialisable objects. 🧑🏫 KNN, HNSW, USEARCH, ANNOY, PYNNDESCENT, FAISS, and VOYAGER. 🔗 Library:
- 🔥 NEW cool NO-CODE solution for clicking together AI WEB APPS! 🎨 Gradio released "gradio sketch" 🚼 Really easy way to create web apps with minimal code. ⚙️ Start with `pip install gradio` & `gradio sketch` 📒 Release: buff.ly/41aeLoA
- Vector Search - let's keep it clean and lightweight! ⚡️ <100K records, no problem! >100K, some scaling issues ANN DuckDB index, sub-second response times Notebook:
- 🔥 The smolagents module has arrived in the agents course! 💻 Code agents optimised for software development 🔧 Tool calling agents that create modular, function-driven workflows 🔍 Retrieval agents designed to access and synthesise information Course: buff.ly/4kcj6Ai
- 🧑🏫 Awesome. My talk for PyCon Italy 2025 got accepted! Got data problems? Relax. Synthetic data is here to help. Talk: buff.ly/3QzoZKj
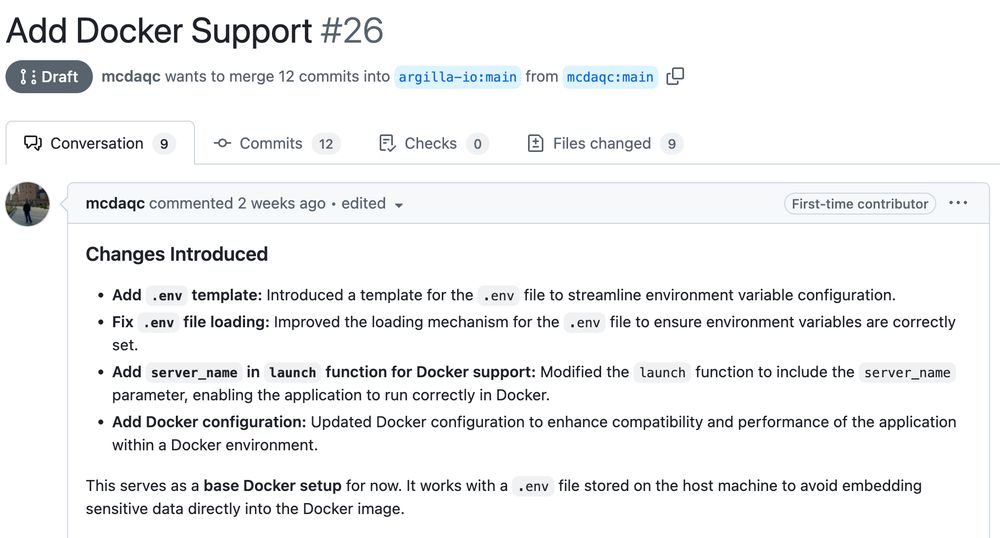
- 🐳 Announcing docker support to Quickly set up your Synthetic Data Generator with (Gradio + Ollama + Argilla)! 🔥 Build genuinely useful datasets using natural language! ⚖️ Scale however you need. 🔐 Use them privately or share them with the world! 🧑💻 GitHub: buff.ly/49IDSmd
- With 80K agent builders joining the agents course, it is time to make agents explorable on the Hub! You can now search and find the perfect agents and tools for your needs! Powered by @Gradio! Start searching:
- Image Generation has landed in Arena form 🎨🤖! 1. Describe your desired image🎨 2. Two anonymous models output images 3. Vote for the winner! Images have been sourced from our Open Image Preference dataset! Dataset: buff.ly/4il0du9 Arena: buff.ly/4142NwH
- Are you, the top of the Agents class?! We just released a bonus unit on function calling (FC). You will learn: ⑴ What is FC? ⑵ Thought → Act → Observe Cycle in FC ⑶ lightweight and efficient fine-tuning Course: buff.ly/3Qn1DHB
- 📹 In case you've missed the hype around smolagents, here is a presentation I gave yesterday at an MLOps community event! library: buff.ly/4hj6PrJ slides: buff.ly/3WUzZ8D video:
- Slides for my MLOps community talk on smolagents! Slides: buff.ly/3WUzZ8D
- 🚀 Find banger tools for your smolagents! I created the Tools gallery, which makes tools specifically developed by/for smolagents searchable and visible. This will help with: - inspiration - best practices - finding cool tools Space: buff.ly/41cYctx
- 🔥 Come and get those AI agents certificates! Join the cohort of 66K students: buff.ly/4hxb6rK
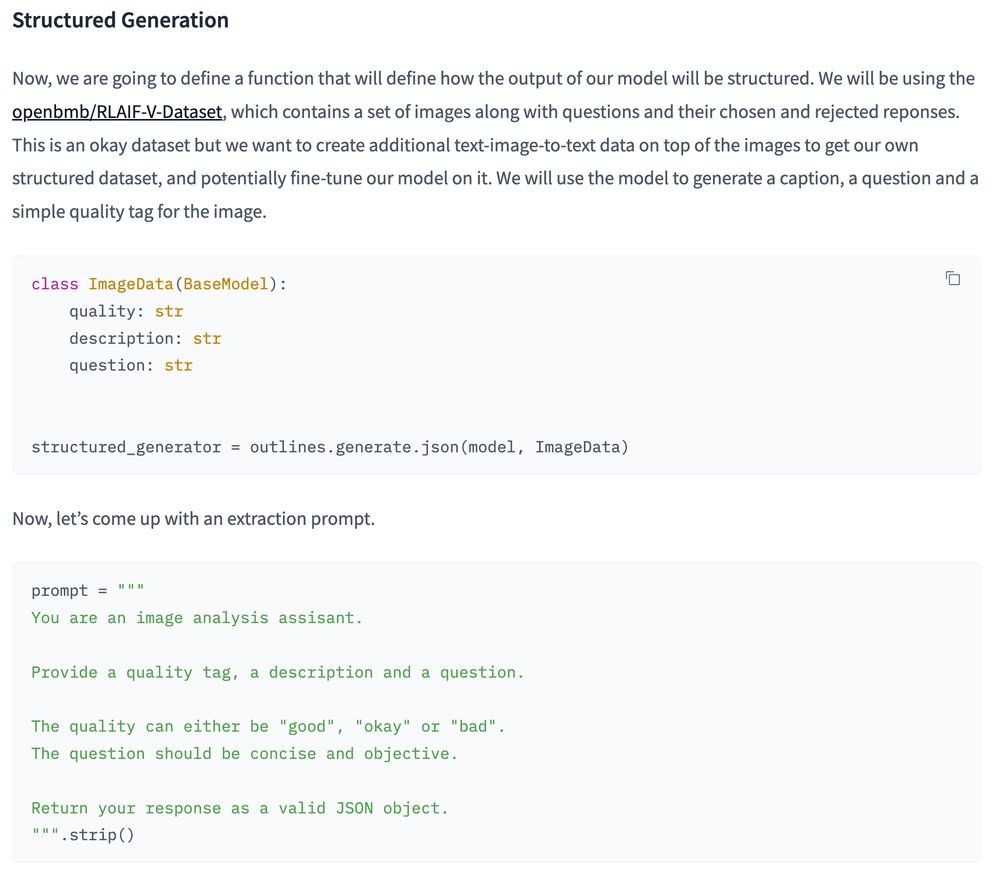
- Documents or images to structured data using Vision Language Models Outlines has an integration with transformers, which facilitates structured generation based on limiting token sampling probabilities. Blog: buff.ly/4jFHMkr
- Local docker deployments for the synthetic data generator 🫱🏾🫲🏼 We would love to hear your thoughts! PR: buff.ly/4hRMny6
- Curious about "Why 🚀", you may wonder? smolagents effortlessness combined with the power of 400,000 AI tools available on the Hub! library: buff.ly/4hj6PrJ
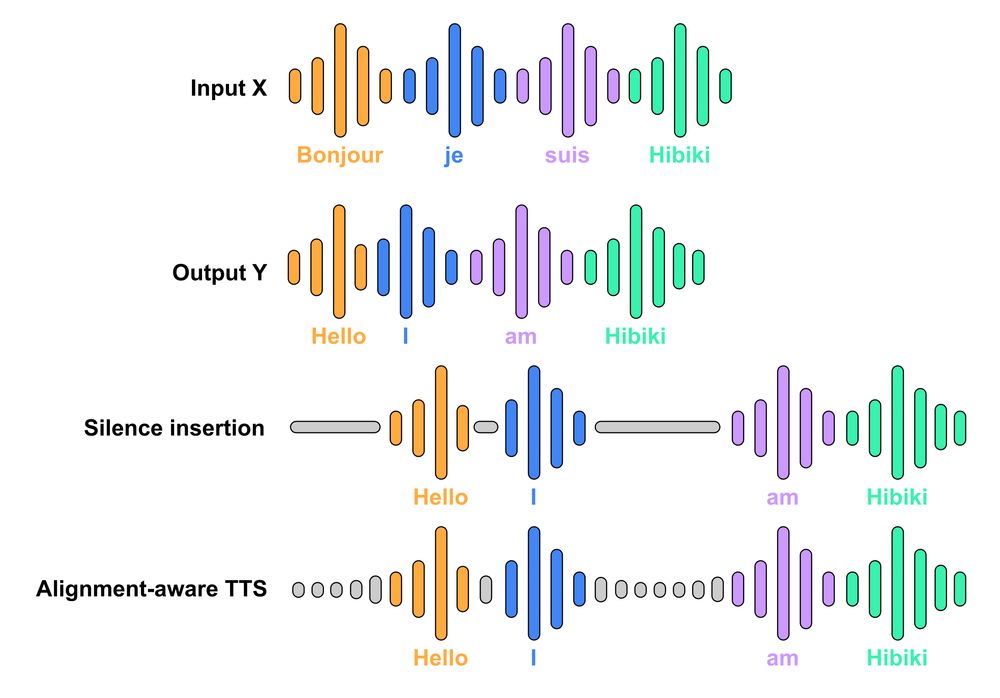
- WOW, this will rock the world! Hibiki is a model for simultaneous speech2speech translation. And it actually works. Available in French-English but super excited to see what the community will do. Hub: buff.ly/3EtmM0f Paper: buff.ly/4jIXNGd
- Agentic RAG: Applied, visual, and step-by-step! 🐾 Get familiar with the Agents and tools, not the bells and whistles! Retrieve - Augment and now GENERATE. Parts: 1: buff.ly/40XNIxM 2: buff.ly/40HkB0x 3:
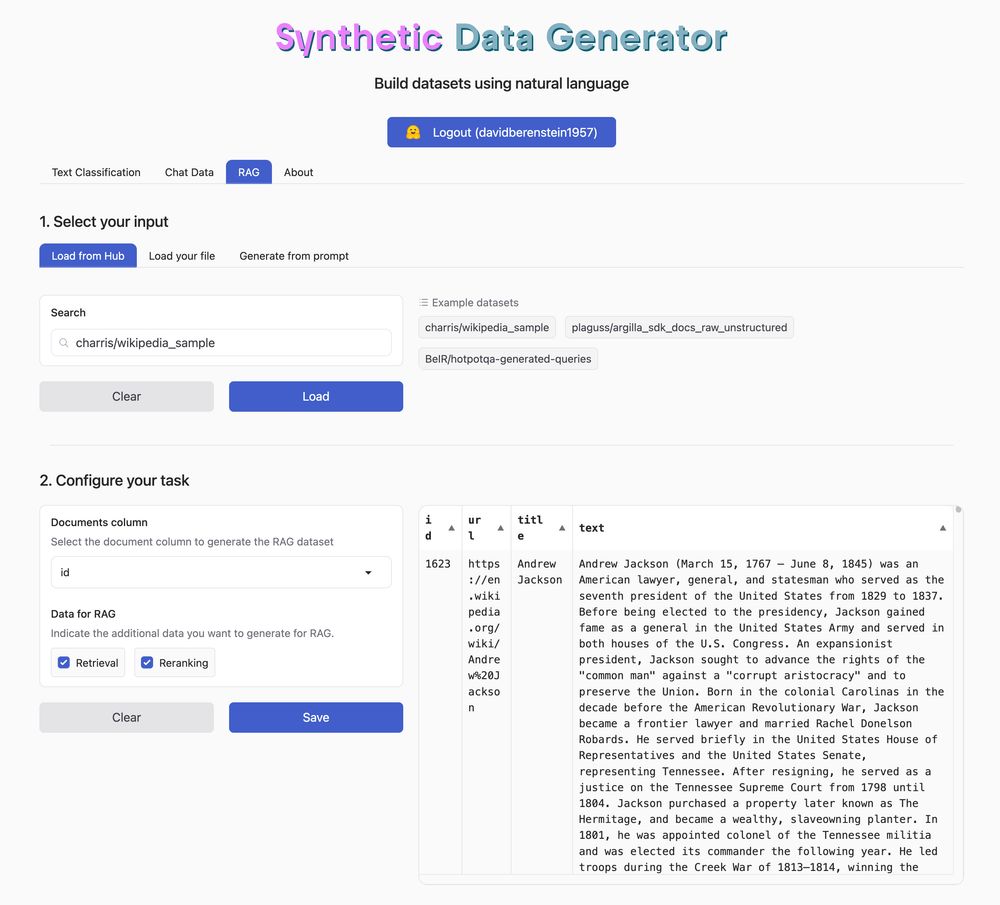
- 🤯 Bring your own AI data, even if you have none! Describe your dataset for RAG, LLMs or Text Classification Bring your own context! Press play and wait Space: buff.ly/3Y1S99z GitHub: buff.ly/49IDSmd
- Anyone can create free hosted tools for their AI agents! 🔥 Agentic RAG stack part 2 - augment Augment retrieval results by reranking optimises content without increasing time too much part2: buff.ly/40HkB0x part1: buff.ly/40XNIxM code: buff.ly/4hEajpj
- 🔥 How to find and install the latest AI apps from the AI app store 1. go to buff.ly/42CnUbU 2. search the app you like 3. go to the bottom settings 4. open the URL 5. press the search bar to install More info: buff.ly/3Csqc2J
- Retrievers and rankers are a crucial part of optimising RAG. Easier to fine-tune than LLMs. More predictable than prompts. Training data is hard to find, so we offer private and free synthetic data on your own documents! Blog:
- Creating an agentic RAG stack on the Hugging Face Hub - part 1 - retrieval (1/5). 🚀 Web apps and microservices included! Chunk, embed and index documents at a huge scale without overhead. Blog:
- Shit! 24B is the new small. Mistral drops their new model on Hugging Face! Great performance, and low latency. Model: buff.ly/4hwAzBa Code: buff.ly/3CEohrF
- Deploy a DeepSeek Web App with minimal code! AI Gradio is a Python package that makes it easy for developers to create AI apps powered by various AI providers. Code: buff.ly/40BDsde Library: buff.ly/3CvOQ2n
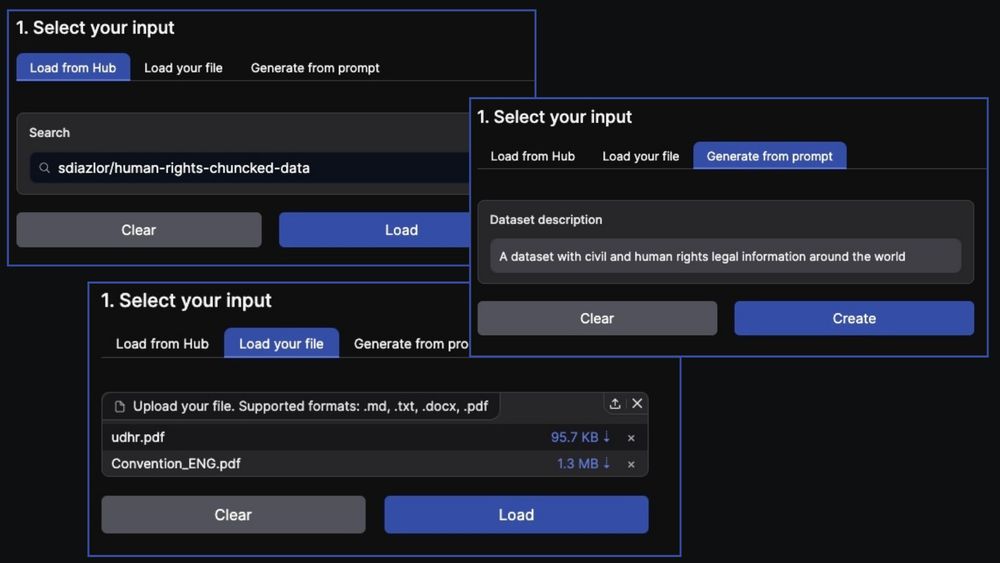
- No data for fine-tuning retrieval models? We help you generate it! - Load from Hub - Upload your own files - Generate from a prompt Space: buff.ly/3Y1S99z Code: buff.ly/3PRg4TX
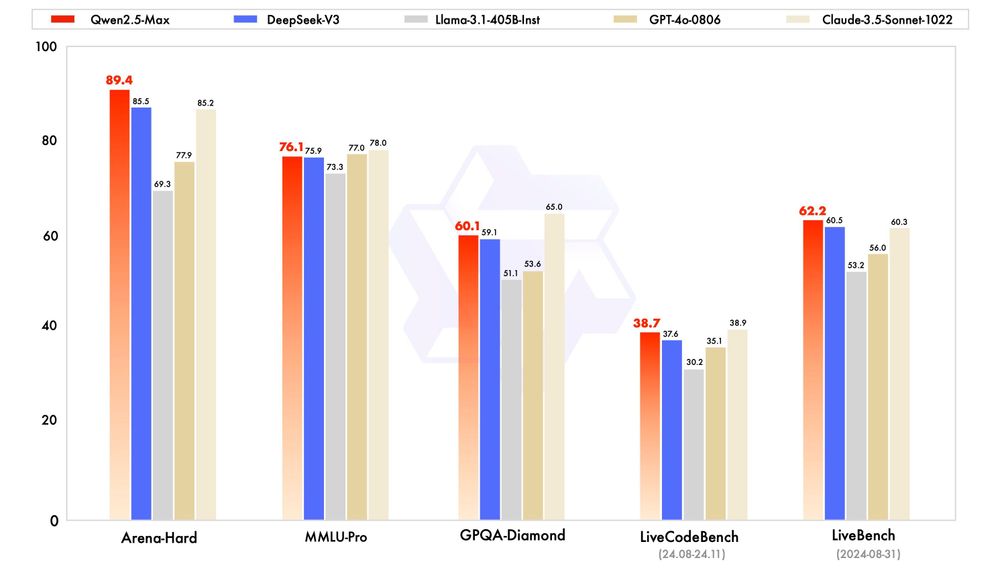
- The Game is Afoot! Qwen2.5-Max! A model that beats DeepSeek V3 on benchmarks. As of now, only available on Alibaba Cloud 🔐 Space: buff.ly/42xUhZ2 Blog:
- ⚡️ Embed 1 million records in <10 minutes Load the data, use static embeddings, and reupload. Ready for vector search but might require some reranking. Library: buff.ly/42miwte
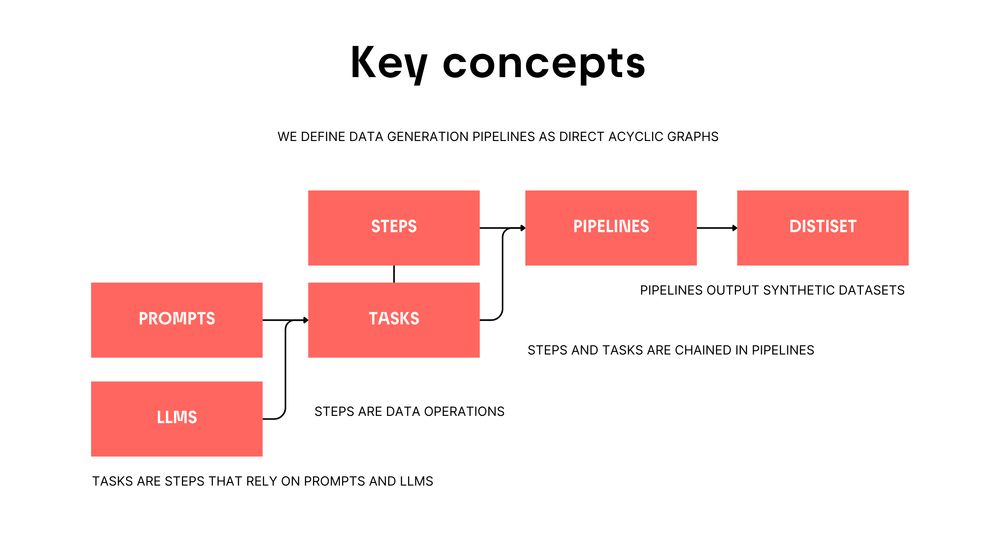
- 🔥 The synthetic data for SmolLM and open DeepSeek-R1 relies on this awesome package! 1.2K distilabel datasets on the Hub buff.ly/3PW46si reproducible and sharable pipelines any LLM provider scale however you want library: buff.ly/3MXAB8G
- Today, we are launching the integration of four awesome serverless Inference Providers – fal, Replicate, Sambanova, Together AI! Want to know how it works? Read the blog: buff.ly/3CreCES
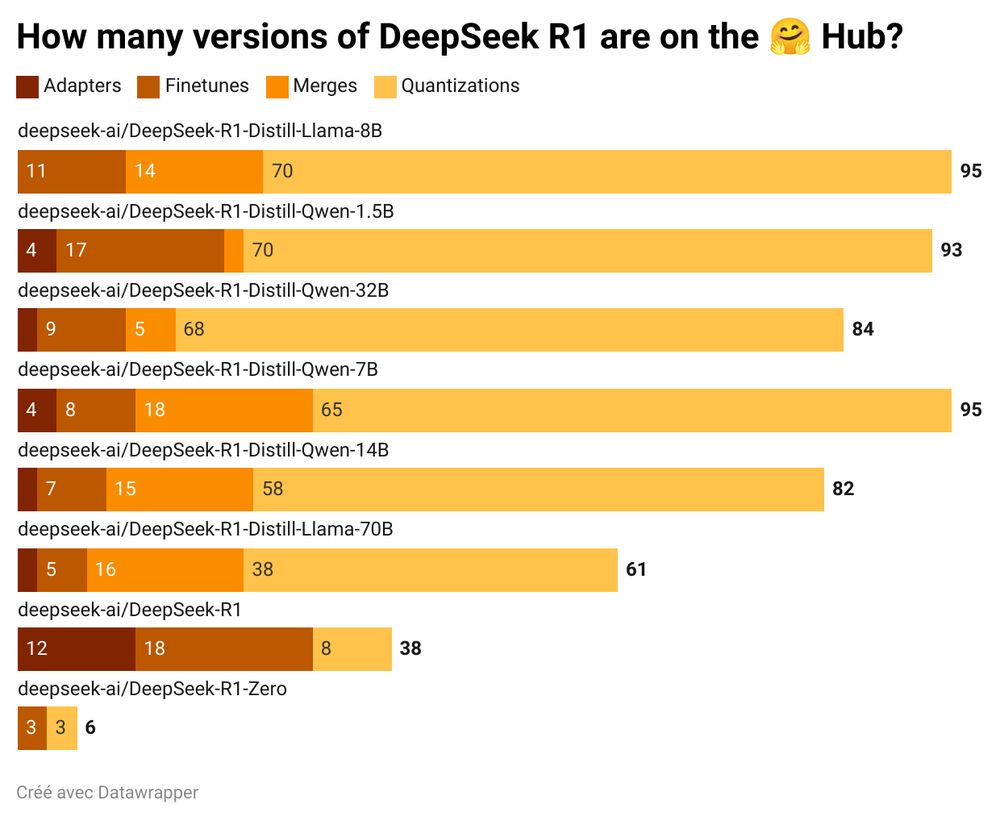
- 🐳 DeepSeek is on Hugging Face 🤗 Free for inference! 1K requests for free 20K requests with PRO Code: buff.ly/4glAAa5 900 models more: buff.ly/40x1rua
- 🐳 DeepSeek-R1 is also available on your Apple device via Hugging Chat! And, so are Meta, Qwen, SmolLM and many many others! Perfect to test and compare for your use case without lock-in. App Store:
- Reposted by David BerensteinYes, DeepSeek R1's release is impressive. But the real story is what happened in just 7 days after: Original release: 8 models, 540K downloads. Just the beginning... The community turned those open-weight models into +550 NEW models on @huggingface. Total downloads? 2.5M—nearly 5X the originals.
- Reposted by David Berenstein[Not loaded yet]
- Let's uncover the post-training dataset from Deepseek-R1 with Magpie! Pass pre-query tokens `<|begin▁of▁sentence|>User: `, let the model generate the rest. We get realistic examples! Gist: buff.ly/40nPHu0 Library: buff.ly/3MXAB8G
- Is RAG less useful due to longer context models?! Qwen at least sees a place for competition and releases its long-context version of Qwen2.5, supporting 1M-token context lengths. 🔥 Models:
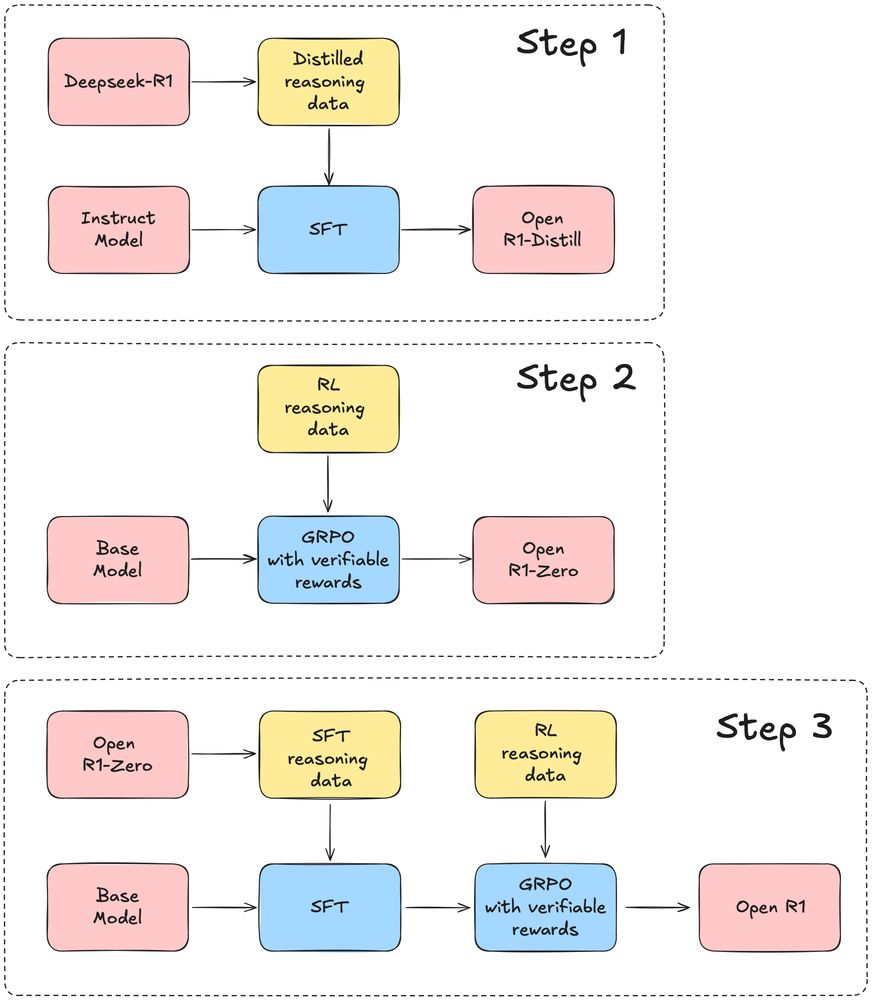
- Awesome! A fully open reproduction of DeepSeek-R1 by the Hugging Face Science team. Three steps - Distill data from R1 - RL pipeline to create R1-Zero - RL-tuned via multi-stage training Repo: buff.ly/4jtbp8x Paper session: buff.ly/4awj2H8
- 🤯 Vector search on top of millions of docs in seconds. no pre-indexing! Model2Vec is an embedding powerhouse that distils good models and makes them up by 500x faster and 15x smaller. Vector Search on Hub Datasets demo: buff.ly/4gYhVlY Library: buff.ly/42miwte
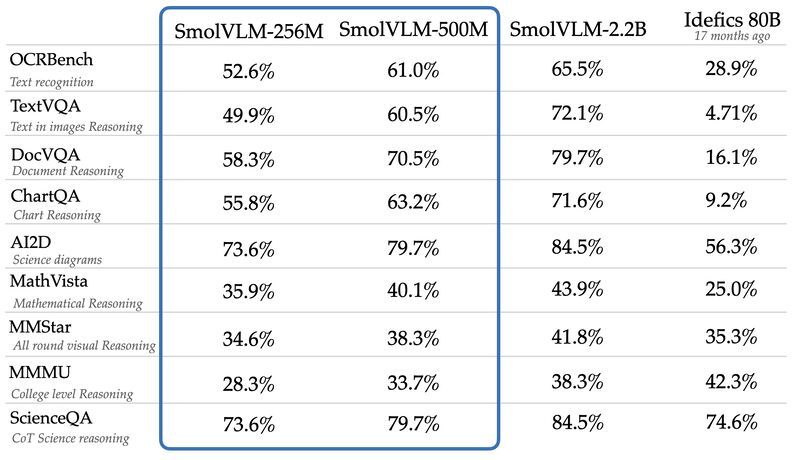
- You might have thought VLMs could not get smoller? 🐁 Hugging Face proves you wrong and launches SmolVLM 256M & 500M. You can fine-tune it on your laptop and run it on your toaster! 👇 🐘 Beats SOTA 80B from less than 2 years ago! Model: buff.ly/4g9bGur
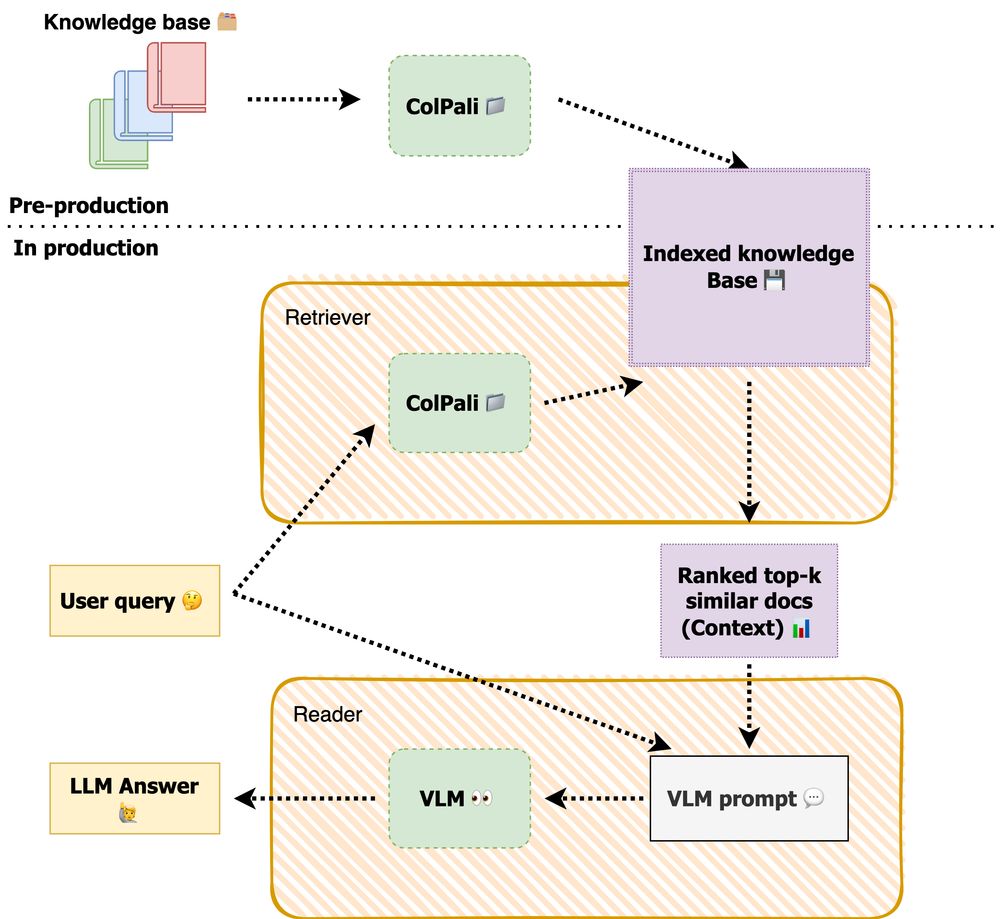
- ColPali and VLMs are great for multi-modal RAG with truly effective document retrieval. Want to set up this pipeline yourself? Read the blog: buff.ly/42rNPTG
- For a while, companies have been showing off their AI competence on the Hub with their datasets, models, and Spaces. Now, you can do the same with more nuance by linking blogs to your organisation! blog: buff.ly/3C3IzLe
- Bootstrap, optimise and maintain domain-specific embedding and reranking in your RAG pipeline through synthetic data generation and evaluation. RAG optimisation can start easily by focusing on smaller and more manageable models. notebook: buff.ly/3PRg4TX UI: buff.ly/3Y1S99z
- The RAG's in the bag! You can now use the Synthetic Data Generator with your own domain-specific seed data to generate a dataset for fine-tuning retrieval or reranking model. GitHub: buff.ly/49IDSmd Spaces: buff.ly/3Y1S99z