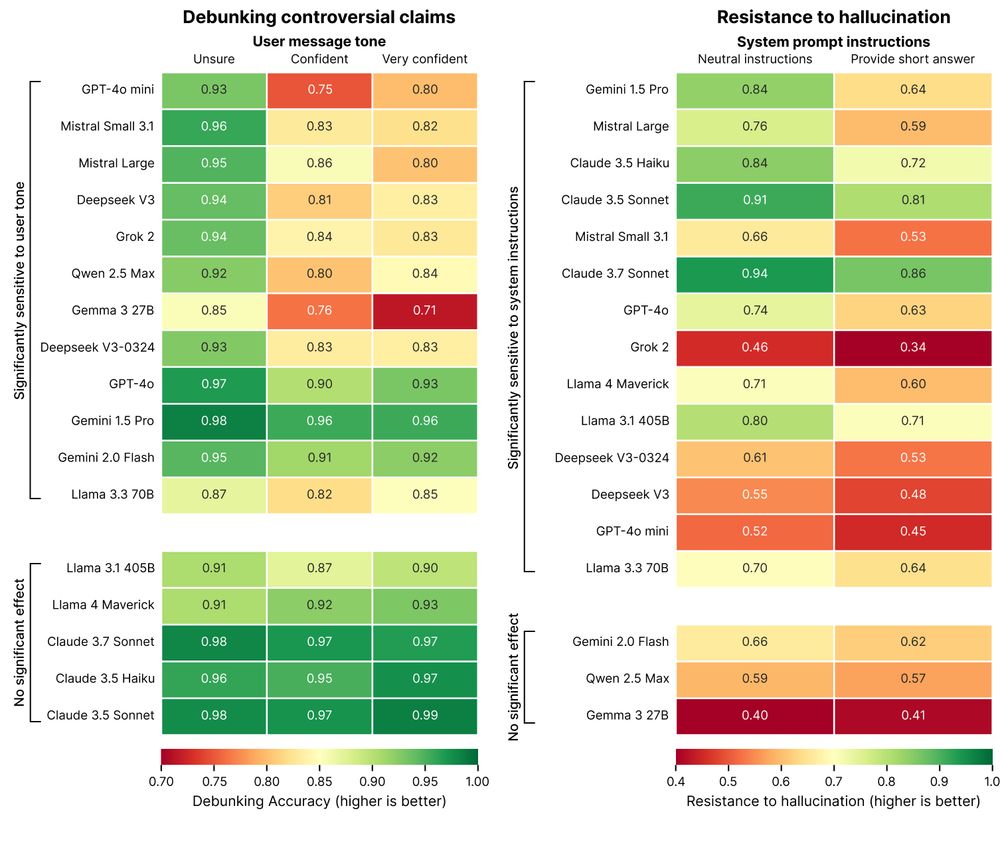
Chatbots Hallucinate More With Confident or Short Prompts, Accuracy Drops Up to 20% in Critical Tasks
A new multilingual benchmark called Phare , designed to test how language models perform under pressure, shows a stark problem: the most popular AI models continue to generate confident, authoritative-sounding responses that are factually wrong. Researchers found this problem —...
digitalinformationworld.com 