
Delta Lake
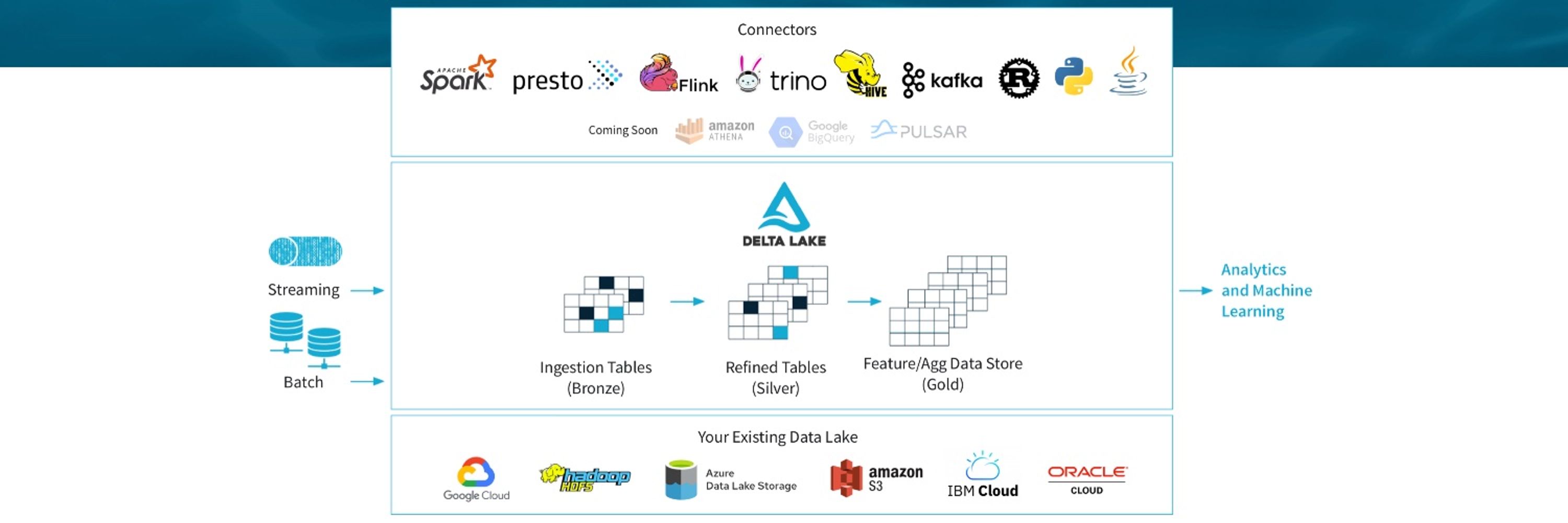
Delta Lake is an open-source storage framework that enables building a Lakehouse architecture for Spark, Flink, Trino, Hive, Scala, Java, Rust, Python, & more.
- Implementing CDC in #DeltaLake? Check out this clip on Change Data Feed (CDF)! You'll learn: ✅ How CDF exposes granular changes between table versions ✅ When (& when not) to enable CDF ✅ How to propagate changes downstream efficiently 🎥 Watch the full conversation: www.youtube.com/live/O8_82Cu...
- Heading to #DataAISummit? Don’t miss this #DeltaLake session! 🚀 Dive into the power of Liquid Clustering—an out-of-the-box solution that automatically tunes your data layout to scale effortlessly with your datasets. ⚡ 📍 San Francisco 🗓️ June 9-12 REGISTER 👉 www.databricks.com/dataaisummit #oss
- 🚀 How do you ensure high performance & reliability when handling concurrent writes in data lakes? R. Tyler Croy shares key insights on how delta-rs delivers performance & reliability for high-throughput workloads, highlighting important considerations for efficient data ingestion at scale. #oss
- Streaming-first data engineering, agentic systems, and automation are reshaping the enterprise data landscape. See how Delta powers this shift at “The Hitchhiker’s Guide to Delta Lake Streaming in an Agentic Universe” at #DataAISummit! 🚀 🗓️ June 9-12 📍 San Francisco 🔗 www.databricks.com/dataaisummit
- ⏰ Time’s running out! Save 50% on your Data+AI Summit ticket with the Delta Lake community promo code! Want the code? 👇 Reply to this post and we’ll DM it to you! This special promotion ends Sunday, May 25. 👉 Learn more: databricks.com/dataaisummit #DeltaLake #DataAISummit #OpenSource
- R. Tyler Croy (Buoyant Data) recently shared how re-architecting his data pipeline with Rust and the oxbow architecture for #DeltaLake writes reduced resource usage to just 1% of the previous setup! 🌱🌐 Want to learn more❓ 🔗 Read the full story: www.buoyantdata.com/blog/2025-04... #opensource
- Git for Delta: Git-Like Branching Meets ACID Guarantees with LakeFS & Delta Lake 🤝 Discover how #lakeFS and #DeltaLake bring Git-style version control, branching, and CI/CD to your data lakes-unlocking new levels of reliability and collaboration! 🗓️ May 21 🕗 9:00AM PT REGISTER 👉 lu.ma/gitfordelta
- Tomorrow is your chance to see how StreamNative Ursa is redefining real-time data pipelines with native #DeltaLake integration! 🦀 Streamline data, handle schema drift, and unify streaming & batch. 🙌 🗓️ Tuesday, May 6 🕓 9:00AM PT 🔗 Secure your spot: lu.ma/deltaxstream... #opensource #oss
- In this clip, Scott Haines & Youssef Mrini break down how Delta tables are structured and why components like the transaction log and checkpoints matter for reliability and performance. Want to learn more❓ 👉 Watch the full session here: www.youtube.com/watch?v=O8_8... #deltalake #opensource #oss
- 🚨 Last chance to register! Join us Tuesday, May 6 at 9AM PT to learn how StreamNative Ursa + #DeltaLake make real-time data pipelines easy: ✅ No custom ETL ✅ Schema-aware writes ✅ Auto compaction ✅ Unified batch + streaming access 🔗 REGISTER: lu.ma/deltaxstream... #opensource #oss #streamnative
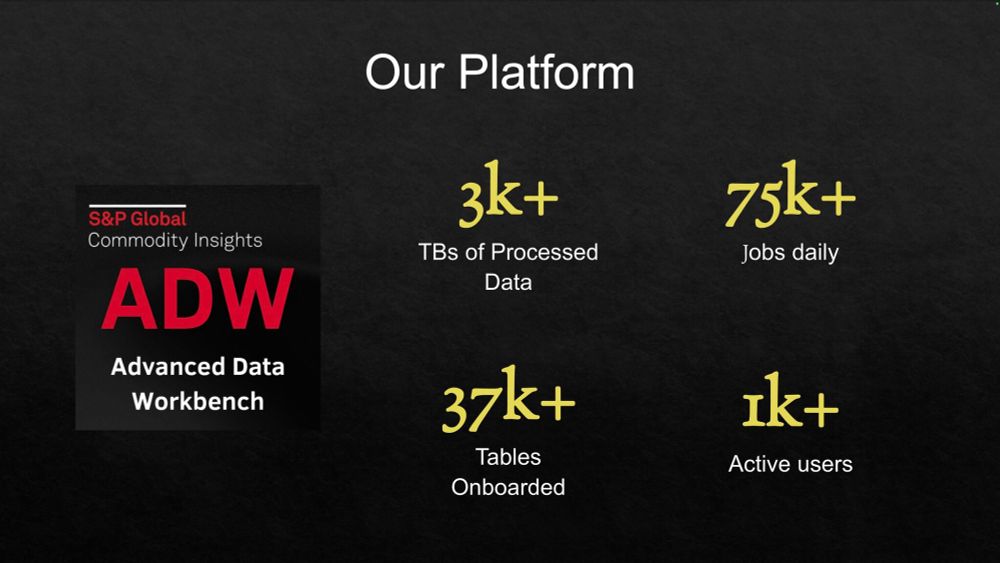
- Just wrapped an amazing session: Rusty Waters: Elevating Lakehouses Beyond Spark 🌊 S&P Global Commodity Insights runs 3K+ TBs of processed data & 75K+ jobs/day! ⚙️ By the numbers, for example, for a 100MB dataset hourly processing workflow, by using AWS Lambdas and #deltars. #opensource #deltalake
- Did you know #DeltaLake lets you reorder columns for faster queries & better stats? Youssef Mrini & Scott Haines explain how putting key columns first speeds up analytics-a major edge over Parquet. Want more Delta Lake tips? 🎥 Watch the full webinar: www.youtube.com/watch?v=O8_8... #opensource
- 🌊 TOMORROW, April 29 at 9AM PT! Learn how delta-rs + CDC are transforming the way lightweight, open lakehouse applications are built. 🚀 Get insights into how S&P Global powers customer value through fast, efficient data solutions without relying on Spark overhead. 🙌 🎟️ RSVP: lu.ma/deltars-spgl...
- 💡 When should you use a deep clone? In this clip, Youssef Mrini & Scott Haines discuss how deep clones enable you to snapshot and relocate your Delta tables — encompassing both data & metadata — efficiently & with minimal disruption to your pipeline. 🎥 Full webinar: www.youtube.com/watch?v=O8_8...
- 💥 Struggling with real-time data in #DeltaLake? Join us to see how StreamNative Ursa tackles schema drift, small files & more—no custom ETL needed! 📅 May 6 at 9AM PT — just two weeks away! 🎙 With Sijie Guo, Kundan Vyas, and host Robert Pack 🔗 Register now: lu.ma/deltaxstream... #opensource #oss
- In this session, Jay Chia explains why Daft is built in #Rust and how it opens the door to faster, more approachable data engines. ✅ Rust’s performance edge ✅ Why #Python + Rust work so well together ✅ A glimpse into the future of multimodal data 🔗 Watch more: www.youtube.com/live/lYCkcTC... #oss
- 🌊 Rusty Waters: Elevating Lakehouses Beyond Spark is coming up Tuesday, April 29 at 9AM PT! Take a practical look at how delta-rs + CDC are helping teams power nimble, high-performance #lakehouse architectures — especially when #Spark is too heavy for your use case. 📅 RSVP: lu.ma/deltars-spgl...
- 🚨 Struggling with real-time ingestion, schema drift, or the small file problem in Delta Lake? Join us to learn how StreamNative Ursa simplifies #DeltaLake pipelines with native support for real-time, schema-aware writes — no custom #ETL required. 📅 May 6 | 9AM PT 🔗 RSVP: lu.ma/deltaxstream...
- 🚨 Happening Today! Ready to get hands-on with #DeltaLake? 🦀 Join us at 9AM PT for a practical deep dive into how to use Delta Lake in real projects. 🚀 Learn how to use it to build faster, cleaner data pipelines. 🎥 Streaming LIVE on YouTube, X & LinkedIn 👉 Register: lu.ma/deltalaketip... #oss
- Ready to get practical with Delta Lake? 🦀 We’re covering structure, transactions, time travel ⏳ & cleanup 🧹 — plus live demos on table creation & performance tuning. 🗓️ April 15 | 9AM PT 🎥 YouTube, X & LinkedIn Learn practical Delta Lake skills you can use right away! RSVP ➡️ lu.ma/deltalaketip...
- "How do you manage dataset optimization and compaction within a streaming-first mindset, especially when you're handling continuous data ingestion & table maintenance at the same time❓" Scott Haines & Denny Lee walk through strategies for handling this problem. 🔗 www.youtube.com/live/k7jxgQZ...
- Tired of the small file problem? Struggling with data skew? Spending too much time tuning partitions and Z-Ordering? Liquid Clustering solves these challenges. 🚀 Dive into the details and see Liquid Clustering in action. 🎥 Full video: www.youtube.com/live/l8CEyXg... #deltalake #opensource #oss
- On Tuesday, April 29, join us to explore delta-rs + CDC, open-source tools powering high-performance, efficient data apps without #Spark. Hear how the S&P Global Commodity Insights team use them to build responsive, scalable solutions for today’s data needs. 🚀 Save your spot 👉 lu.ma/deltars-spgl...
- 🚨 Happening today: Beyond JVMs: Reinventing Catalogs with Daft & Delta Lake For Python users building data pipelines, analytics, and ML workflows — we’re going deep on how #Daft brings performance and simplicity to #DeltaLake. 🗓️ April 7 at 10AM PT 🔗 Join us live → lu.ma/BeyondJVMs #opensource
- ⏰ Clock’s ticking! Have you signed up for our Delta Lake Tips, Tricks, and Best Practices webinar? Join us for a deep dive into #DeltaLake fundamentals and pro techniques you can use immediately. 🗓️ April 15 | 9AM PT 🎥 Live on YouTube, X & LinkedIn Secure your spot now ➡️ lu.ma/deltalaketip...
- Don't miss Beyond JVMs – Reinventing Catalogs with Daft & #DeltaLake happening this Monday at 10AM PT! 🙌 Discover how Daft brings a native Python experience to Delta Lake, making data engineering, analytics, and ML/AI workflows faster & easier—with zero Java dependencies! 🔗 RSVP: lu.ma/BeyondJVMs
- "Every year, the amount of data being generated increases exponentially—so how do we keep up❓" With Liquid Clustering, you can define clustering columns based on query patterns and let the system automatically optimize performance. 📈 🎥 Learn more: www.youtube.com/watch?v=l8CE... #opensource #oss
- 📢 One week from today - April 7 @ 10AM PT! Join us to explore: ✅ Faster #DeltaLake reads with parallelization & data skipping ✅ A full-featured DataFrame API for seamless ML/AI transformations ✅ How Daft unifies modern data & ML stacks, making data ingestion effortless 🔗 Register: lu.ma/BeyondJVMs
- 🚨 Delta Lake Tips, Tricks, and Best Practices Dive into the core principles of #DeltaLake, from transaction management to powerful features like time travel ⏳. Discover how to create tables, execute transactions & optimize performance. ✅ 🗓️ April 15 | 9AM PT RSVP ➡️ lu.ma/deltalaketip... #oss
- #Spark excels with big data, but for smaller workloads, its overhead can slow things down. What if you could get high performance without Spark? Join us as we dive into delta-rs + CDC and how they power lightweight, high-performance data apps! 🚀 📅 April 29 | 9 AM PT RSVP 👉 lu.ma/deltars-spgl...
- 🚨 Reminder: Today at 9 AM PT! Join us for a deep dive into Hybrid Clustering—combining liquid clustering with hive-style partitioning for optimized data performance. 🎙️ Topic: Optimize performance without sacrificing flexibility 🎥 Tune in LIVE on YouTube & LinkedIn 🔗 RSVP: lu.ma/uo4v6bb1
- 🚨 Data Engineers! TOMORROW, March 25 @ 9AM PT: Learn hybrid clustering best practices—combining liquid clustering flexibility & hive-style partitioning reliability. 🎥 Live w/ Scott Haines & Robert Pack on LinkedIn & YouTube. RSVP ➡️ lu.ma/uo4v6bb1 #opensource #deltalake #oss #linuxfoundation
- DuckDB just dropped a new blog about getting the best performance when reading #DeltaLake tables—packed with insights & benchmarks. The blog post highlights three new features designed to speed things up: ⚡ Metadata caching 📂 File skipping 📦 Partition pushdown Read more: duckdb.org/2025/03/21/m...
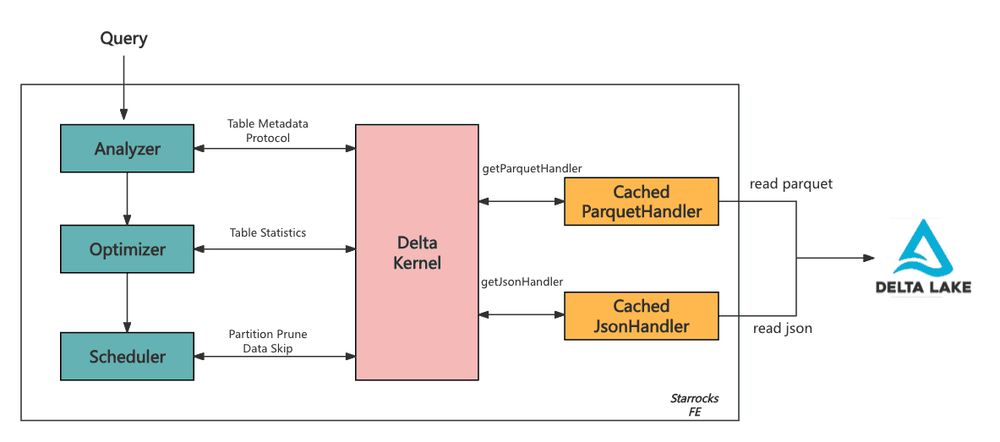
- 🚀 Optimizing Customer-Facing Analytics with Delta Kernel StarRocks accelerates queries with Delta Kernel’s Engine APIs, reducing redundant Parquet & JSON reads and improving cache efficiency. This boosts performance and responsiveness for high-concurrency workloads. 🔗 delta.io/blog/starroc...
- 🤔 How fast can you process a 10M-row CSV into Delta Lake? Daniel Beach put Daft to the test by reading a 1.1GB CSV (10 million lines) and writing it to Delta Lake—all in just 3 minutes on AWS Lambda. 🚀 🎥 Watch the full webinar: www.youtube.com/watch?v=BR9o... #deltalake #opensource #awslambda
- Java dependencies once blocked Python users from Delta Lake & Iceberg. Now, tools like PyIceberg are changing that—but what if we could go further? 🤔🚀 Join us to explore Daft, a next-gen data engine redefining catalogs in Python! 📅 Apr 7 | 10 AM PT 🔗 Register: lu.ma/BeyondJVMs #deltalake #oss
- 🔥 Struggling with performance bottlenecks in your data pipelines? In this session, we'll unpack hybrid clustering, share real-world use cases, and walk through strategies to enhance performance without losing flexibility. ✅ 📅 Tuesday, March 25 | 9AM PT 🔗 Save your spot: lu.ma/uo4v6bb1 #deltalake